Train a Covid19 Tweet sentiment classifier using Bert
Setup
Download and move data files to data folder.
pip install kaggle
New-Item ~\.kaggle\kaggle.json
notepad C:\Users\<user>\.kaggle\kaggle.json
kaggle datasets download -d datatattle/covid-19-nlp-text-classification
jupyter notebook
pip install torch===1.7.0+cu110 -f https://download.pytorch.org/whl/torch_stable.html
pip install transformers numpy pandas matplotlib jupyter
import pandas as pd
import torch
import numpy as np
import matplotlib.pyplot as plt
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1'
torch.cuda.device_count()
2
Data Analysis
train = pd.read_csv('../data/Corona_NLP_train.csv', encoding='ISO-8859-1')
test = pd.read_csv('../data/Corona_NLP_test.csv', encoding='ISO-8859-1')
pd.set_option('display.max_colwidth', 150)
train.head()
| UserName | ScreenName | Location | TweetAt | OriginalTweet | Sentiment | |
|---|---|---|---|---|---|---|
| 0 | 3799 | 48751 | London | 16-03-2020 | @MeNyrbie @Phil_Gahan @Chrisitv https://t.co/iFz9FAn2Pa and https://t.co/xX6ghGFzCC and https://t.co/I2NlzdxNo8 | Neutral |
| 1 | 3800 | 48752 | UK | 16-03-2020 | advice Talk to your neighbours family to exchange phone numbers create contact list with phone numbers of neighbours schools employer chemist GP s... | Positive |
| 2 | 3801 | 48753 | Vagabonds | 16-03-2020 | Coronavirus Australia: Woolworths to give elderly, disabled dedicated shopping hours amid COVID-19 outbreak https://t.co/bInCA9Vp8P | Positive |
| 3 | 3802 | 48754 | NaN | 16-03-2020 | My food stock is not the only one which is empty...\r\r\n\r\r\nPLEASE, don't panic, THERE WILL BE ENOUGH FOOD FOR EVERYONE if you do not take more... | Positive |
| 4 | 3803 | 48755 | NaN | 16-03-2020 | Me, ready to go at supermarket during the #COVID19 outbreak.\r\r\n\r\r\nNot because I'm paranoid, but because my food stock is litteraly empty. Th... | Extremely Negative |
plt.style.use('ggplot')
_ = plt.hist(train.Sentiment)
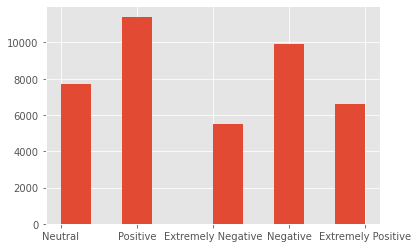
labels = {label: i for i, label in enumerate(train.Sentiment.unique())}
index_to_labels = {i:label for i, label in enumerate(train.Sentiment.unique())}
labels,index_to_labels
({'Neutral': 0,
'Positive': 1,
'Extremely Negative': 2,
'Negative': 3,
'Extremely Positive': 4},
{0: 'Neutral',
1: 'Positive',
2: 'Extremely Negative',
3: 'Negative',
4: 'Extremely Positive'})
Data Processing
- Train Test Split
- dataset creation
from torch.utils.data import random_split
from torch.utils.data import Dataset, DataLoader
class TweetDataset(Dataset):
def __init__(self, df):
self.df = df[['OriginalTweet', 'Sentiment']]
self.labels = labels
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
row = self.df.iloc[idx]
return (row.OriginalTweet, self.labels[row.Sentiment])
train_ds = TweetDataset(train)
test_ds = TweetDataset(test)
print(train_ds[0])
train_ds, val_ds = random_split(train_ds,[len(train_ds)-5000,5000])
print('train_ds, train_ds, test_ds', len(train_ds), len(val_ds), len(test_ds))
('@MeNyrbie @Phil_Gahan @Chrisitv https://t.co/iFz9FAn2Pa and https://t.co/xX6ghGFzCC and https://t.co/I2NlzdxNo8', 0)
train_ds, train_ds, test_ds 36157 5000 3798
- Data loder
- Tokenization
- Tensor creation
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained('distilbert-base-uncased')
def collate_fn(batch):
tweets, labels = torch.utils.data._utils.collate.default_collate(batch)
tokens = tokenizer( list(tweets), max_length = 128, padding = True, truncation = True, return_tensors = 'pt')
tokens['labels'] = labels
return tokens
train_dataloder = DataLoader(train_ds,collate_fn= collate_fn, batch_size = 16)
val_dataloder = DataLoader(val_ds,collate_fn= collate_fn, batch_size = 16)
batch = iter(train_dataloder).next()
batch.keys()
dict_keys(['input_ids', 'attention_mask', 'labels'])
Model
Remove head from encoder later
model = AutoModelForSequenceClassification.from_pretrained('distilbert-base-uncased',num_labels = len(labels) )
Hyper Params
epochs = 2
max_train_steps_per_epoch = 3000
max_val_steps_per_epoch = 100
max_lr = 4E-5
log_steps = 1
Device
device = 'cuda:0'
def check_memory(text= ''):
print(f'{text} : GPU memory: %.1f' % (torch.cuda.memory_allocated() // 1024 ** 2))
check_memory()
model = model.to(device)
: GPU memory: 0.0
Train
def train_step(batch, batch_id):
outputs = model.forward(**batch)
loss = outputs.loss
return loss
def val_step(batch, batch_id):
# check_memory('Before val step')
outputs = model.forward(**batch)
loss = outputs.loss
logits = outputs.logits
# check_memory('After val step')
return loss, logits
Optimizer and Scheduler
from torch.optim import Adam
from torch.optim.lr_scheduler import OneCycleLR
optimizer = Adam(model.parameters(), lr = max_lr)
scheduler = OneCycleLR(
optimizer,
max_lr=3E-5,
steps_per_epoch=max_train_steps_per_epoch,
epochs=epochs,
anneal_strategy = 'linear')
check_memory()
: GPU memory: 256.0
train_losses = []
val_losses = []
val_accs = []
lrs = []
import torch.autograd.profiler as profiler
from tqdm.notebook import tqdm
# with profiler.profile(profile_memory=True, record_shapes=True) as prof:
for epoch in tqdm(range(1, epochs+1)):
# print(f'Epoch : {epoch}')
# print('Training')
model.train()
check_memory()
for i, batch in tqdm(enumerate(train_dataloder)):
batch = batch.to(device)
if i>=max_train_steps_per_epoch:
break
loss = train_step(batch, i)
loss.backward()
optimizer.step()
optimizer.zero_grad()
scheduler.step()
lrs.append(scheduler.get_last_lr()[0])
if i%log_steps == 0:
train_losses.append(loss.detach())
# print(f'Training batch {i+1}, loss = {loss}')
print('Validating')
model.eval()
val_loss = []
same = 0
total = len(val_dataloder)
for i, batch in tqdm(enumerate(val_dataloder)):
batch = batch.to(device)
if i>=max_val_steps_per_epoch:
break
output = val_step(batch, i)
loss = output[0]
logits = output[1]
val_loss.append(loss.detach())
same += (torch.argmax(logits) == batch.labels).sum()
if i%log_steps == 0:
# print(f'Validating batch {i+1}, loss = {loss}')
pass
val_losses.append(torch.stack(val_loss).mean())
val_accs.append(same/total)
print('Finished training .. ')
HBox(children=(HTML(value=''), FloatProgress(value=0.0, max=2.0), HTML(value='')))
: GPU memory: 256.0
HBox(children=(HTML(value=''), FloatProgress(value=1.0, bar_style='info', layout=Layout(width='20px'), max=1.0…
Validating
HBox(children=(HTML(value=''), FloatProgress(value=1.0, bar_style='info', layout=Layout(width='20px'), max=1.0…
: GPU memory: 1531.0
HBox(children=(HTML(value=''), FloatProgress(value=1.0, bar_style='info', layout=Layout(width='20px'), max=1.0…
Validating
HBox(children=(HTML(value=''), FloatProgress(value=1.0, bar_style='info', layout=Layout(width='20px'), max=1.0…
Finished training ..
# print(prof.key_averages().table(sort_by="self_cuda_memory_usage", row_limit=10))
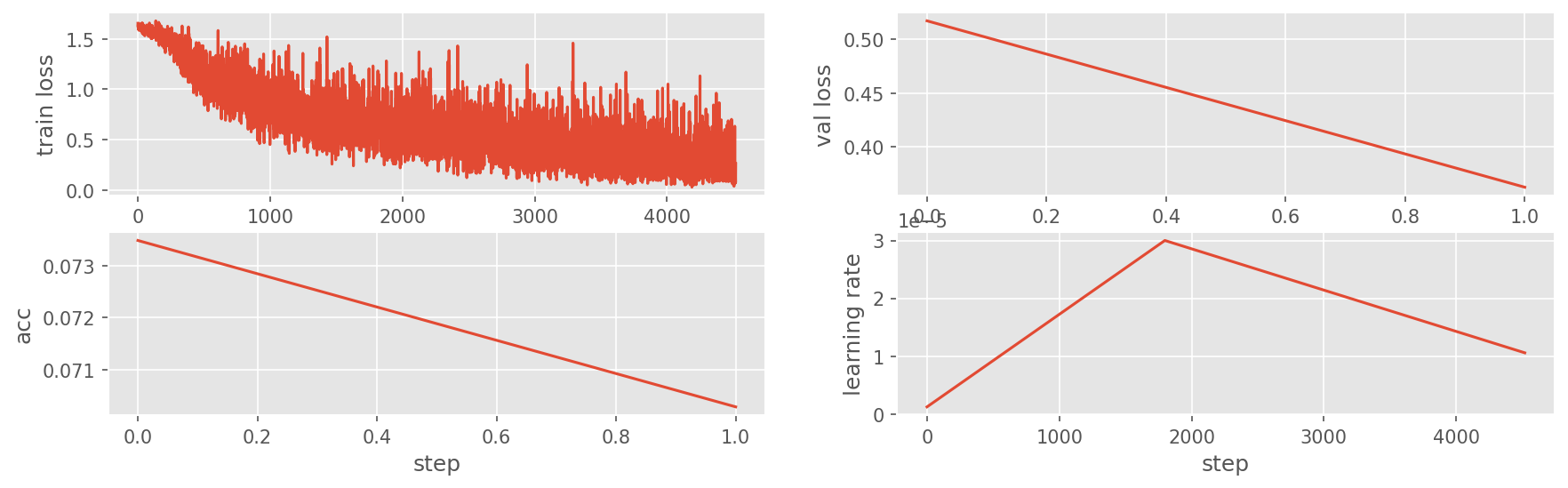
Analyze training
import matplotlib.pyplot as plt
fig, axes = plt.subplots(2,2)
fig.set_figwidth(14)
fig.set_dpi(150)
ax = axes[0][0]
ax.plot(train_losses)
ax.set_xlabel('step')
ax.set_ylabel('train loss')
ax = axes[0][1]
ax.plot(val_losses)
ax.set_xlabel('step')
ax.set_ylabel('val loss')
ax = axes[1][0]
ax.plot(val_accs)
ax.set_xlabel('step')
ax.set_ylabel('acc')
ax = axes[1][1]
ax.plot(lrs)
ax.set_xlabel('step')
ax.set_ylabel('learning rate')
Text(0, 0.5, 'learning rate')
Inference
import torch
def inference(tweets):
print(tweets)
tokens = tokenizer( list(tweets), max_length = 128, padding = True, truncation = True, return_tensors = 'pt')
outputs = model.forward(**tokens.to(device))
logits = outputs[0]
return index_to_labels[torch.argmax(logits).item()]
for i in range(10):
print(f'Truth = {index_to_labels[test_ds[i][1]]} , prediction = {inference([test_ds[i][0]])}\n')
['TRENDING: New Yorkers encounter empty supermarket shelves (pictured, Wegmans in Brooklyn), sold-out online grocers (FoodKick, MaxDelivery) as #coronavirus-fearing shoppers stock up https://t.co/Gr76pcrLWh https://t.co/ivMKMsqdT1']
Truth = Extremely Negative , prediction = Negative
["When I couldn't find hand sanitizer at Fred Meyer, I turned to #Amazon. But $114.97 for a 2 pack of Purell??!!Check out how #coronavirus concerns are driving up prices. https://t.co/ygbipBflMY"]
Truth = Positive , prediction = Positive
['Find out how you can protect yourself and loved ones from #coronavirus. ?']
Truth = Extremely Positive , prediction = Extremely Positive
['#Panic buying hits #NewYork City as anxious shoppers stock up on food&medical supplies after #healthcare worker in her 30s becomes #BigApple 1st confirmed #coronavirus patient OR a #Bloomberg staged event?\r\r\n\r\r\nhttps://t.co/IASiReGPC4\r\r\n\r\r\n#QAnon #QAnon2018 #QAnon2020 \r\r\n#Election2020 #CDC https://t.co/29isZOewxu']
Truth = Negative , prediction = Negative
['#toiletpaper #dunnypaper #coronavirus #coronavirusaustralia #CoronaVirusUpdate #Covid_19 #9News #Corvid19 #7NewsMelb #dunnypapergate #Costco One week everyone buying baby milk powder the next everyone buying up toilet paper. https://t.co/ScZryVvsIh']
Truth = Neutral , prediction = Neutral
['Do you remember the last time you paid $2.99 a gallon for regular gas in Los Angeles?Prices at the pump are going down. A look at how the #coronavirus is impacting prices. 4pm @ABC7 https://t.co/Pyzq8YMuV5']
Truth = Neutral , prediction = Neutral
['Voting in the age of #coronavirus = hand sanitizer ? #SuperTuesday https://t.co/z0BeL4O6Dk']
Truth = Positive , prediction = Positive
['@DrTedros "We canÂ\x92t stop #COVID19 without protecting #healthworkers.\r\r\nPrices of surgical masks have increased six-fold, N95 respirators have more than trebled & gowns cost twice as much"-@DrTedros #coronavirus']
Truth = Neutral , prediction = Negative
['HI TWITTER! I am a pharmacist. I sell hand sanitizer for a living! Or I do when any exists. Like masks, it is sold the fuck out everywhere. SHOULD YOU BE WORRIED? No. Use soap. SHOULD YOU VISIT TWENTY PHARMACIES LOOKING FOR THE LAST BOTTLE? No. Pharmacies are full of sick people.']
Truth = Extremely Negative , prediction = Extremely Negative
['Anyone been in a supermarket over the last few days? Went to do my NORMAL shop last night & ??is the sight that greeted me. Barmy! (Btw, whatÂ\x92s so special about tinned tomatoes? ????????????). #Covid_19 #Dublin https://t.co/rGsM8xUxr6']
Truth = Extremely Positive , prediction = Extremely Positive