Visualizing Bert Embeddings
Set up tensorboard for pytorch by following this blog.
Bert has 3 types of embeddings
- Word Embeddings
- Position embeddings
- Token Type embeddings
We will extract Bert Base Embeddings using Huggingface Transformer library and visualize them in tensorboard.
Clear everything first
! powershell "echo 'checking for existing tensorboard processes'"
! powershell "ps | Where-Object {$_.ProcessName -eq 'tensorboard'}"
! powershell "ps | Where-Object {$_.ProcessName -eq 'tensorboard'}| %{kill $_}"
! powershell "rm -Force -Recurse runs\*"
Create a summary writer
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('runs/testing_tensorboard_pt')
Now let’s fetch the pretrained bert Embeddings.
import transformers
model = transformers.BertModel.from_pretrained('bert-base-uncased')
Word embeddings
tokenizer = transformers.BertTokenizer.from_pretrained('bert-base-uncased')
words = tokenizer.vocab.keys()
word_embedding = model.embeddings.word_embeddings.weight
writer.add_embedding(word_embedding,
metadata = words,
tag = f'word embedding')
Position Embeddings
position_embedding = model.embeddings.position_embeddings.weight
writer.add_embedding(position_embedding,
metadata = np.arange(position_embedding.shape[0]),
tag = f'position embedding')
Token type Embeddings
token_type_embedding = model.embeddings.token_type_embeddings.weight
writer.add_embedding(token_type,
metadata = np.arange(token_type_embedding.shape[0]),
tag = f'tokentype embeddings')
writer.close()
Run tensorboard
From the same folder as the notebook
tensorboard --logdir="C:\Users\...<current notebook folder path>\runs"
Visualizations
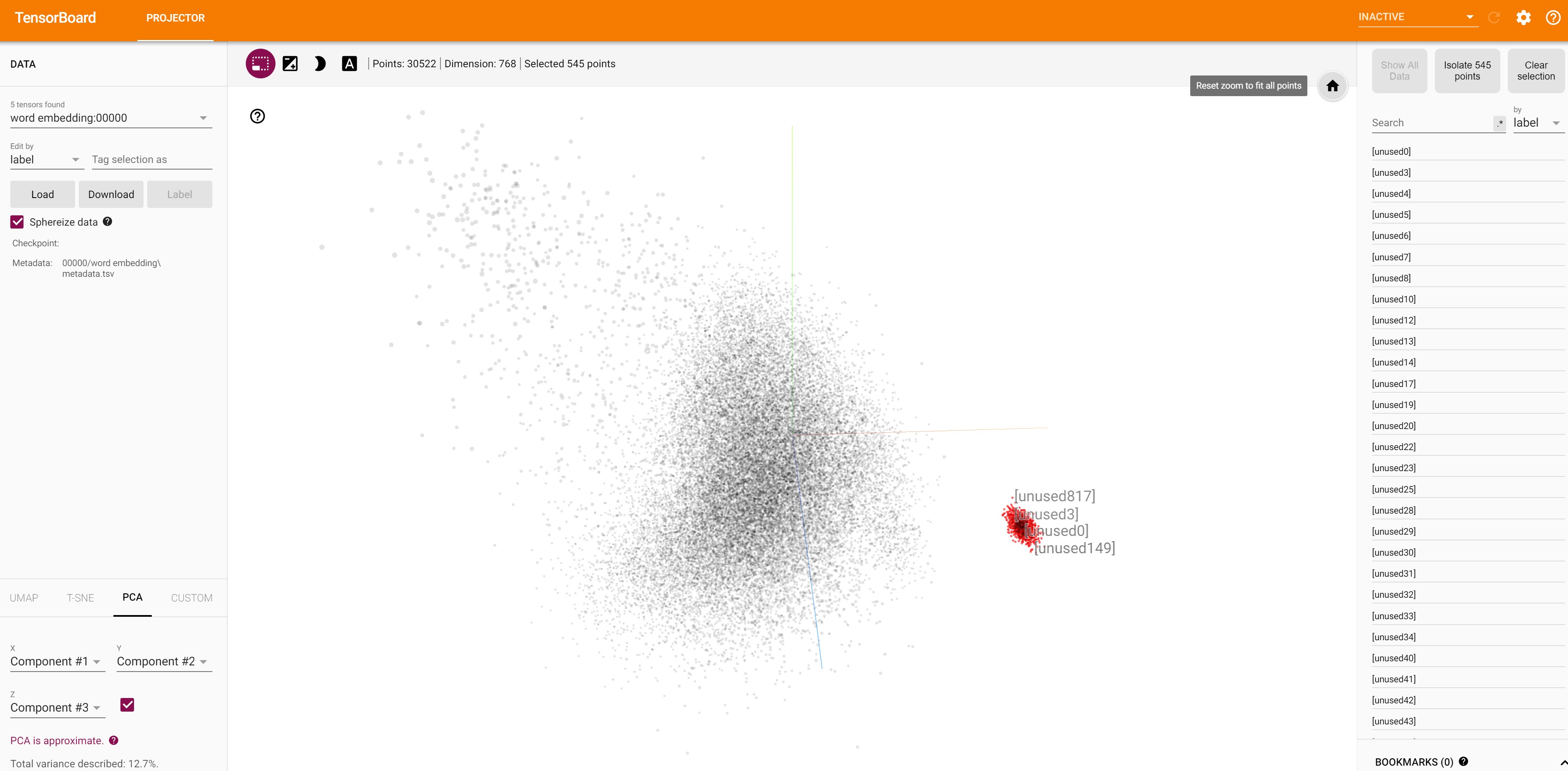
-
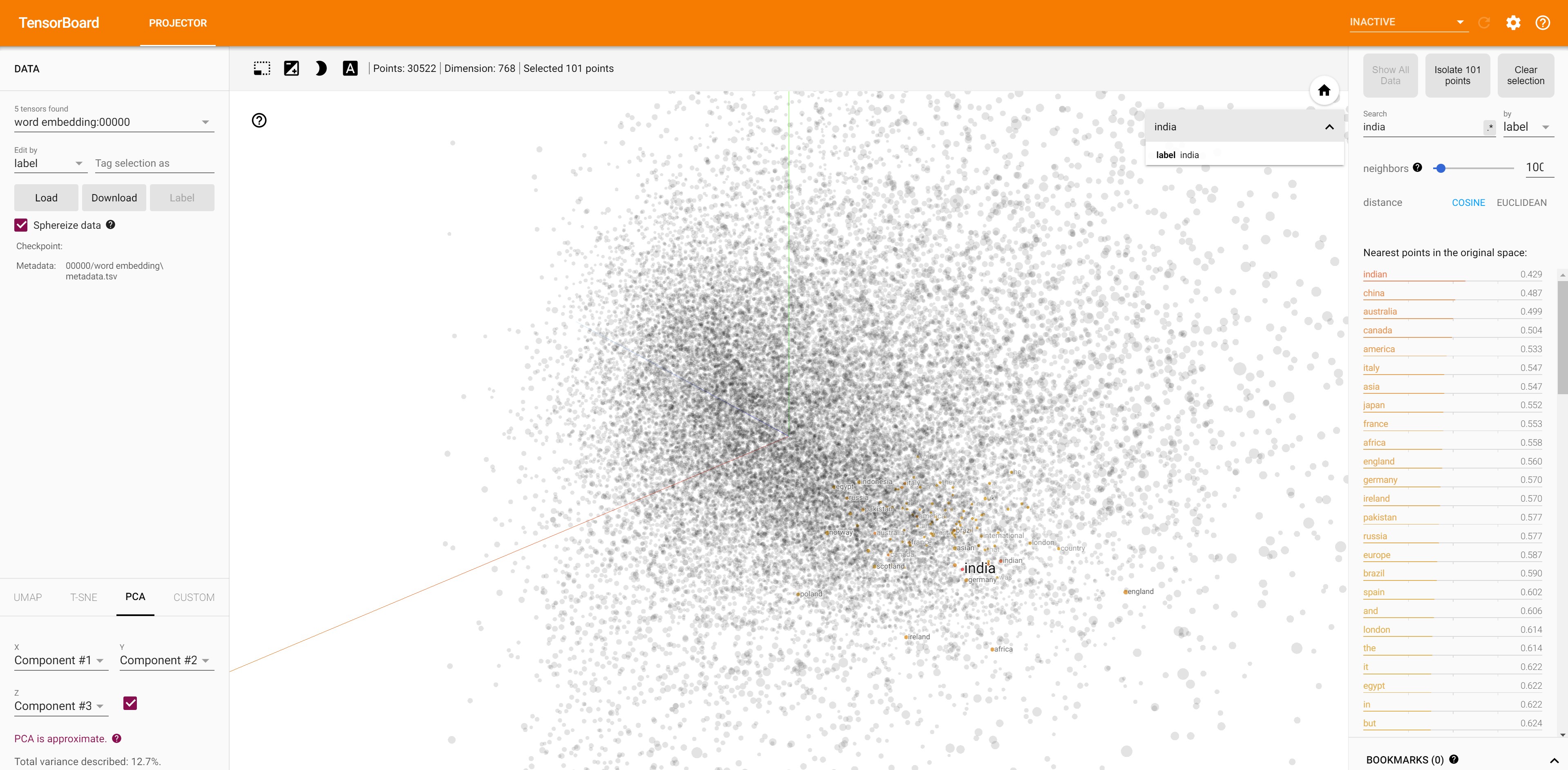
All the country names are closer to India embeddings.
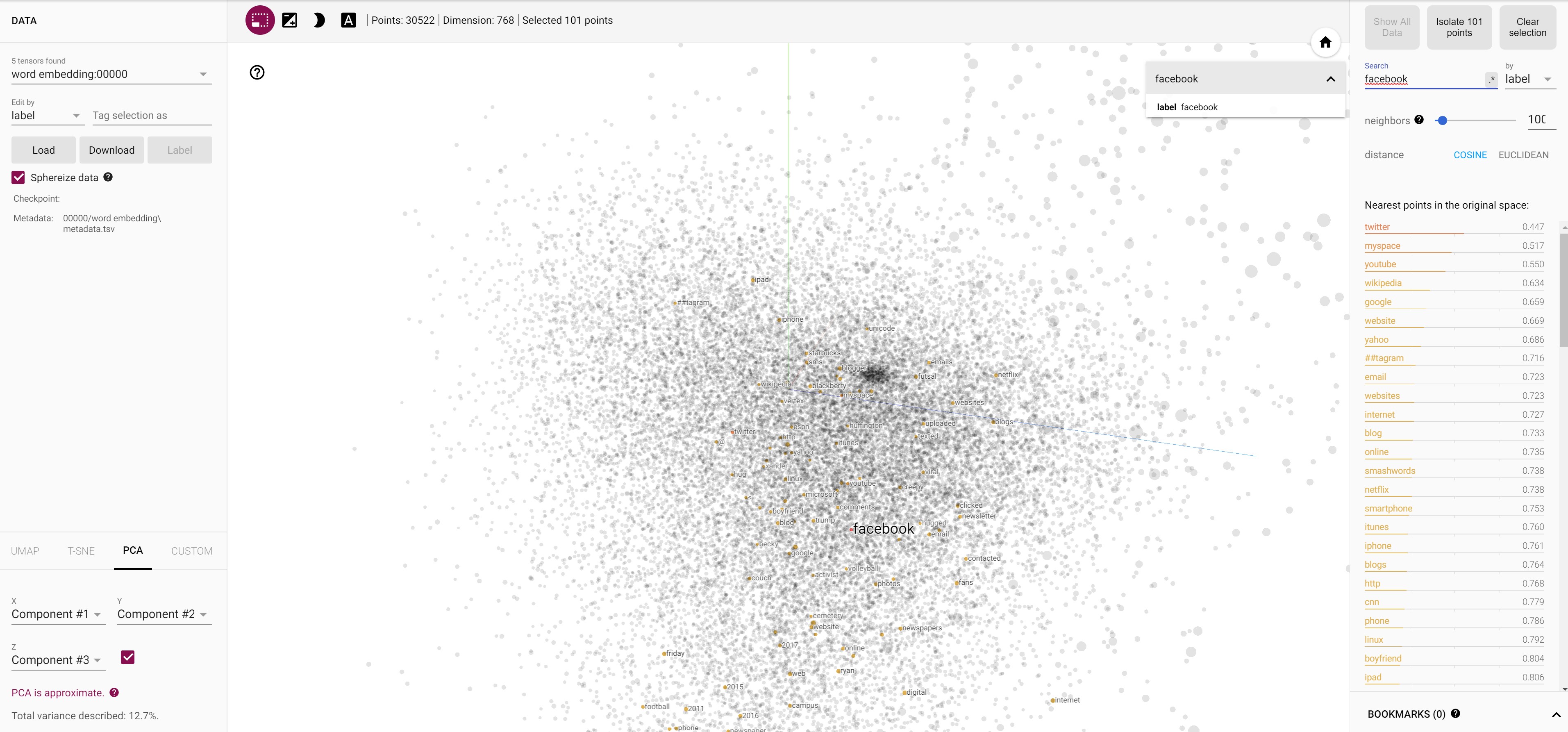
- All the social networking site names are closer to Facebook embeddings.
-
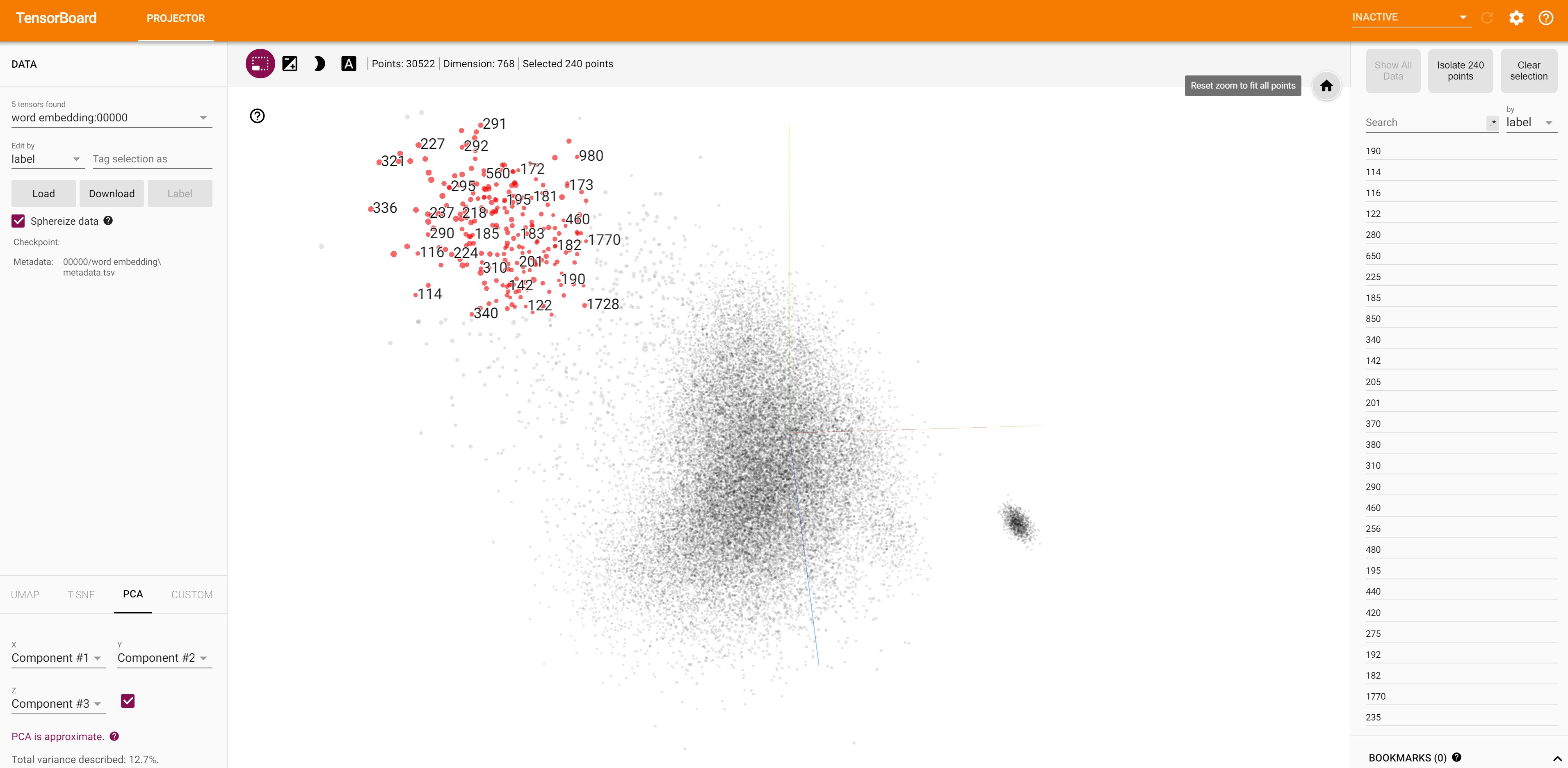
Embedding of numbers are closer to one another.
-
Unused embeddings are closer.
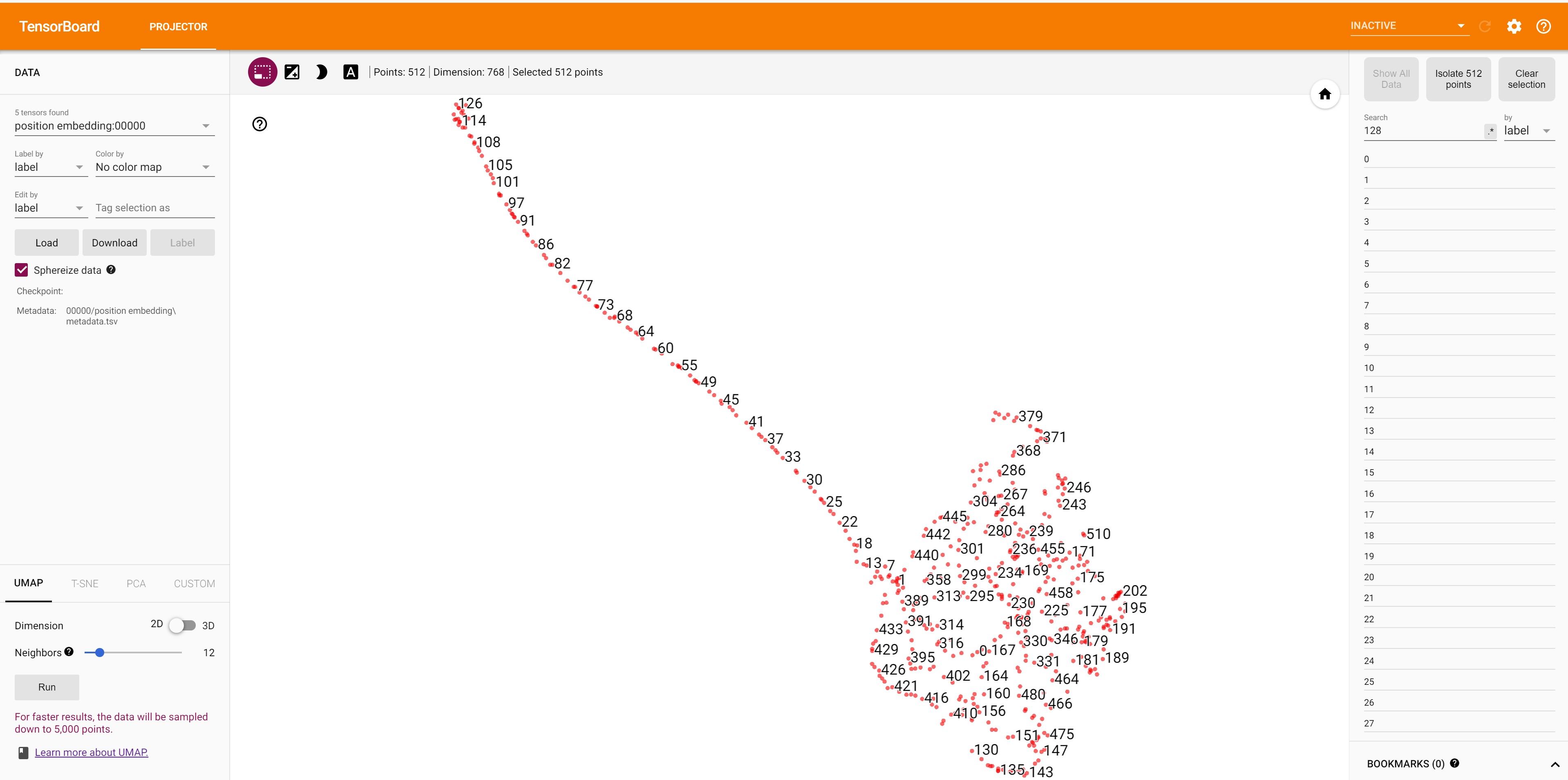
- In UMAP visualization, positional embeddings from 1-128 are showing one distribution while 128-512 are showing different distribution. This is probably because bert is pretrained in two phases. Phase 1 has 128 sequence length and phase 2 had 512.
Contextual Embeddings
The power of BERT lies in it’s ability to change representation based on context. Now let’s take few examples and see if embeddings change based on context.
For this we will only take the embeddings for final layer as those have the maximum high level context.
Dataset with different word senses will be the best way to visualize the representations.I used this word sense disambiguation dataset from Kaggle for analysis. https://www.kaggle.com/udayarajdhungana/test-data-for-word-sense-disambiguation
Download and unzip
# !pip install xlrd
import pandas as pd
examples = pd.read_excel('test data for WSD evaluation _2905.xlsx')
pd.set_option('display.max_colwidth', 1000)
examples = examples.set_index(examples.sn)
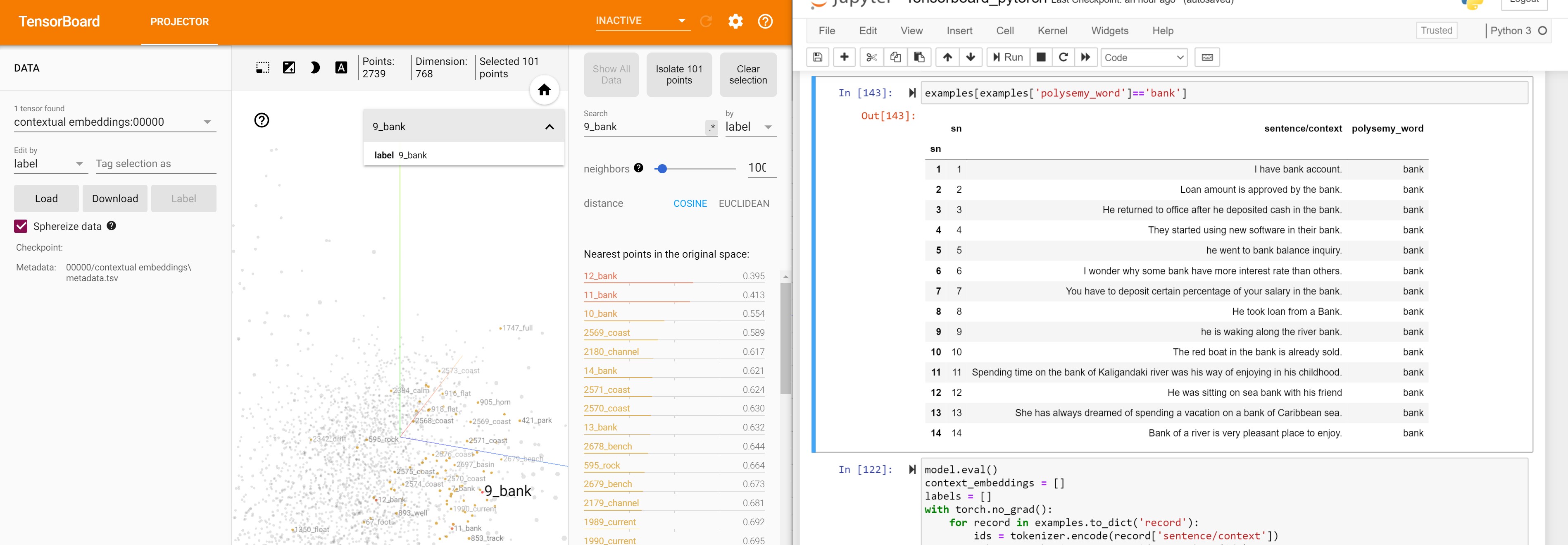
examples[examples['polysemy_word']=='bank']
| sn | sentence/context | polysemy_word | |
|---|---|---|---|
| sn | |||
| 1 | 1 | I have bank account. | bank |
| 2 | 2 | Loan amount is approved by the bank. | bank |
| 3 | 3 | He returned to office after he deposited cash in the bank. | bank |
| 4 | 4 | They started using new software in their bank. | bank |
| 5 | 5 | he went to bank balance inquiry. | bank |
| 6 | 6 | I wonder why some bank have more interest rate than others. | bank |
| 7 | 7 | You have to deposit certain percentage of your salary in the bank. | bank |
| 8 | 8 | He took loan from a Bank. | bank |
| 9 | 9 | he is waking along the river bank. | bank |
| 10 | 10 | The red boat in the bank is already sold. | bank |
| 11 | 11 | Spending time on the bank of Kaligandaki river was his way of enjoying in his childhood. | bank |
| 12 | 12 | He was sitting on sea bank with his friend | bank |
| 13 | 13 | She has always dreamed of spending a vacation on a bank of Caribbean sea. | bank |
| 14 | 14 | Bank of a river is very pleasant place to enjoy. | bank |
model.eval()
context_embeddings = []
labels = []
with torch.no_grad():
for record in examples.to_dict('record'):
ids = tokenizer.encode(record['sentence/context'])
tokens = tokenizer.convert_ids_to_tokens(ids)
#print(tokens)
bert_output = model.forward(torch.tensor(ids).unsqueeze(0),encoder_hidden_states = True)
final_layer_embeddings = bert_output[0][-1]
#print(final_layer_embeddings)
for i, token in enumerate(tokens):
if record['polysemy_word'].lower().startswith(token.lower()):
#print(f'{record["sn"]}_{token}', final_layer_embeddings[i])
context_embeddings.append(final_layer_embeddings[i])
labels.append(f'{record["sn"]}_{token}')
# break
# print(context_embeddings, labels)
writer.add_embedding(torch.stack(context_embeddings),
metadata = labels,
tag = f'contextual embeddings')
writer.close()
Restart tensorboard.
Delete existing logs if necessary and create the writer again using the instructions on top. This will speed up the loading.
ps | Where-Object {$_.ProcessName -eq 'tensorboard'}| %{kill $_}
tensorboard --logdir="<current dir path>\runs"
Open tensorboard UI in browser. It might take a while to load the embeddings. Keep refreshing the browser.
http://localhost:6006/#projector&run=testing_tensorboard_pt
Visualize contextual embeddings
Now same words with different meanings should be farther apart. Let’s analyze the word bank which has 2 different meanings. example 1-8 refer to banks as financial institutes, while example 9-14 use bank mostly as the land alongside or sloping down to a river or lake.
Let’s see if Bert was able to figure this out
Banks as financial institutes
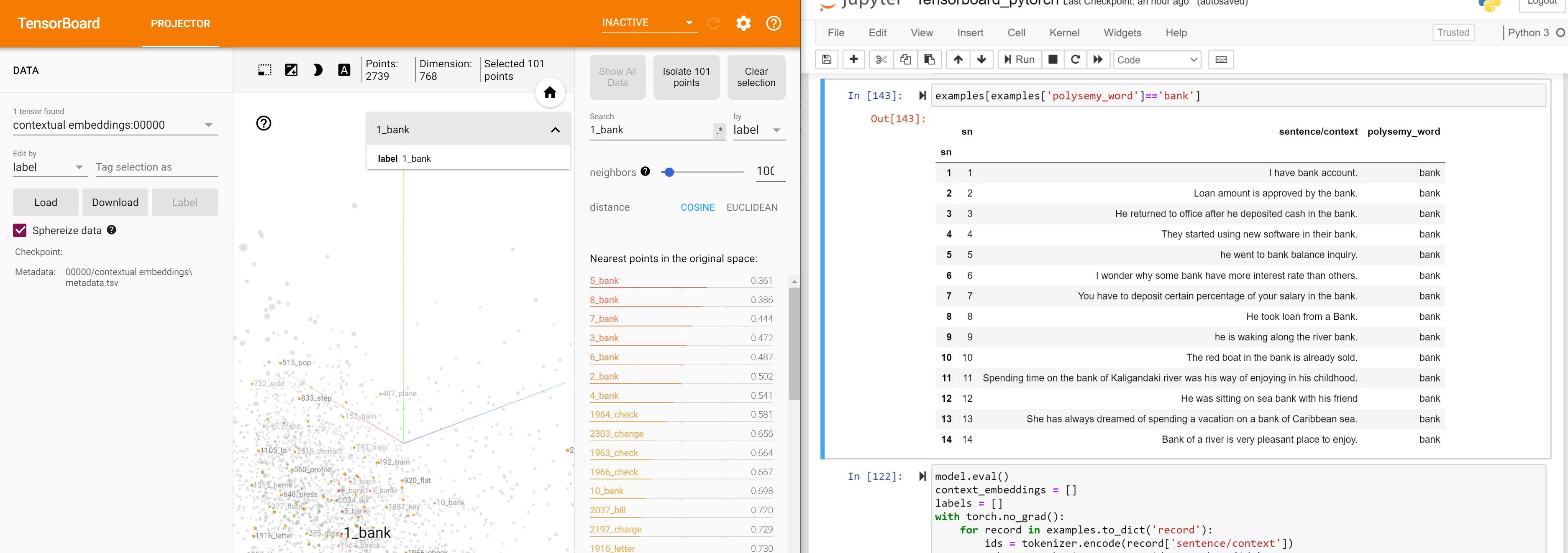
Embeddings of bank in examples 9-14 are not close to the bank embeddings in 9-14. They are close to bank embeddings in example 2-8.
Banks as river sides
bank embedding of example 9 is closer to bank embeddings of example 10-14