Issue with Gradient accumulation while using apex (Fix included)
- Nvidia Apex is used for mixed precission training. Mixed precission training provides faster computatio using tensor cores and a lower memory footprint.
- Gradient accumulation is used to accomodate a bigger batch size than what the GPU memory supports. If my gradient accumulation is 2, I will be doing optimizer.step() once in every 2 steps. For steps where optimizer is not stepping up, only the gradients are accumulated.
- In distributed training, gradients are averaged across all the processes at every loss.backward step which is also called the all-reduce step.
- Apex mixed precission training does the communication in floating point 16.
- Even with floating point 16, doing reduction at every step can be costly. To avoid reduction at every step, an obvious optimization will be to avoid reduction when optimizer is not stepping up.
In latest apex amp library, if reduction is disabled, it results in inaccurate gradients across processes. The following test is only for OPT_LEVEL O2. For OPT_LEVEL O1, there are other issues not highlighted in this blog
O2 maintains two sets of weights and gradients.
- Model weights and gradient (FP16)
- Master weights and gradients(FP32)
More on this official link from NVIDIA
Model weights are used for gradient calculation using scaled loss. Master weights are used while stepping up optimizer and weight updatation. But all-reduce is also conducted on model weights. This created a problem if reductions is disabled while accumulating gradients.
The following flowchart explains what is hapening. Because master gradients go out of sync, the models in different processes update their weights differently without using information from other processes. This impacts convergence and leads to bad results while training.
Solution
There are 2 solutions to this problem.
- Delay unscale. Accumulate gradients in model parameter. Just before optimizer step enable all reduce and remove delay.
- Delay unscale. Disable reduction. Just before optimizer steps up, remove delay Add gradients from master to model (FP16). Do all reduce on model parameters. Exit context manager.
Method 1
After looking at the apex code for scale_loss, I found a way to accumulate gradients in model parameter.
The flag delay_unscale , if set to True, model grads are not copied to master grads.
Apex documentation on scale_loss:
If Amp is using explicit FP32 master params, only the FP32 master gradients will be unscaled. The direct .grad attributes of any FP16 model params will remain scaled after context manager exit.
delay_unscale (bool, optional, default=False) – delay_unscale is never necessary, and the default value of False is strongly recommended. If True, Amp will not unscale the gradients or perform model->master gradient copies on context manager exit. delay_unscale=True is a minor ninja performance optimization and can result in weird gotchas (especially with multiple models/optimizers/losses), so only use it if you know what you’re doing. “Gradient accumulation across iterations” under Advanced Amp Usage illustrates a situation where this CAN (but does not need to) be used.
But one thing missing in apex documentation is that delay_unscale also accumulated gradients in model parameter, which was clear after seeing the code.
Apex code reference:
if not delay_unscale:
if isinstance(optimizers, list):
for optimizer in optimizers:
if not optimizer._amp_stash.params_have_scaled_gradients:
optimizer._prepare_amp_backward()
Code where model grads are reset to zero at every step
def prepare_backward_with_master_weights(self):
stash = self._amp_stash
self._amp_lazy_init()
for i, param in enumerate(stash.all_fp16_params):
param.grad = None
Example code
Source code reproducing the behaviour with a simple linear model.
import torch
torch.manual_seed(47)
model = torch.nn.modules.Linear(1,1)
def print_params(model):
for param in model.named_parameters():
print (f'{param[0]} = {param[1]}, grad = {param[1].grad}')
print_params(model)
weight = Parameter containing:
tensor([[-0.8939]], requires_grad=True), grad = None
bias = Parameter containing:
tensor([-0.9002], requires_grad=True), grad = None
Test basic gradient accumulation without apex
Gradients get accumulated and added up in grad variable of tensors
def train_step(model, input):
out = model(input)
loss = out.mean()
loss.backward()
print_params(model)
input = torch.tensor([[1.0]])
model = torch.nn.modules.Linear(1,1)
model = model
for i in range(3):
print(f'\nstep = {i+1}')
train_step(model,input)
step = 1
weight = Parameter containing:
tensor([[-0.0647]], requires_grad=True), grad = tensor([[1.]])
bias = Parameter containing:
tensor([0.7514], requires_grad=True), grad = tensor([1.])
step = 2
weight = Parameter containing:
tensor([[-0.0647]], requires_grad=True), grad = tensor([[2.]])
bias = Parameter containing:
tensor([0.7514], requires_grad=True), grad = tensor([2.])
step = 3
weight = Parameter containing:
tensor([[-0.0647]], requires_grad=True), grad = tensor([[3.]])
bias = Parameter containing:
tensor([0.7514], requires_grad=True), grad = tensor([3.])
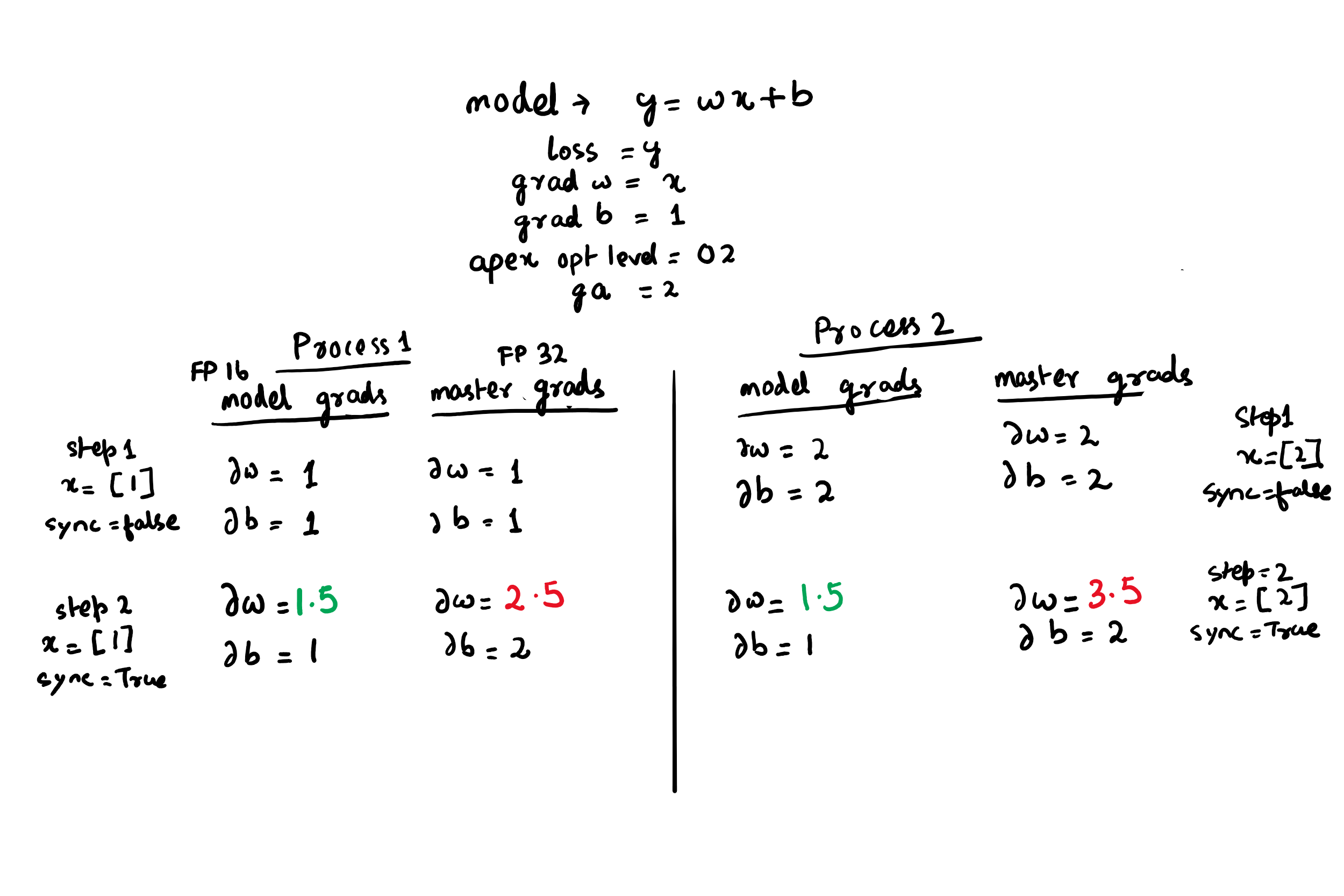
FP16 and DDP
Gradients in model parameters(FP16) are reset and are scaled gradients. Gradients in master parameter (FP32) are always accumulated until explicity set to zero. During every scaled_loss.backward() step
- model grads are reset to zero
- Loss tensor is scaled and backward() operation is called on the scaled loss.
- scaled gradients are calculated in FP16 and saved to model parameters.
- If all reduce is enabled , they are averaged across all the parallel processes.
- Gradients are moved to FP32 , unscaled and added(sum) to master gradients.
But in DDP, reduction happens on model gradients not master gradients(which are not accumulated). If gradient accumulation is >1, this will result in an uneven weigh update across processes.
def fp_16train_step(model, input):
out = model(input)
loss = out.mean()
with amp.scale_loss(loss,optimizer) as scaled_loss:
scaled_loss.backward()
process = 1 #disable this for process 2
#process = 2 #enable this for process 2
if process ==1:
rank =0
device = 'cuda:0'
device_id = 0
input_cpu = torch.tensor([[1.0]])
if process ==2:
rank =1
device = 'cuda:1'
device_id = 1
input_cpu = torch.tensor([[2.0]])
from apex import amp
from apex.amp import _amp_state
gpu = torch.device(device)
model = torch.nn.modules.Linear(1,1)
model = model.to(gpu)
optimizer = torch.optim.SGD(model.parameters(), lr = 0.1)
optimizer.param_groups
[{'params': [Parameter containing:
tensor([[0.1121]], device='cuda:0', requires_grad=True),
Parameter containing:
tensor([0.5968], device='cuda:0', requires_grad=True)],
'lr': 0.1,
'momentum': 0,
'dampening': 0,
'weight_decay': 0,
'nesterov': False}]
model,optimizer = amp.initialize(model, optimizer, opt_level='O2',loss_scale= 1.0)
Selected optimization level O2: FP16 training with FP32 batchnorm and FP32 master weights.
Defaults for this optimization level are:
enabled : True
opt_level : O2
cast_model_type : torch.float16
patch_torch_functions : False
keep_batchnorm_fp32 : True
master_weights : True
loss_scale : dynamic
Processing user overrides (additional kwargs that are not None)...
After processing overrides, optimization options are:
enabled : True
opt_level : O2
cast_model_type : torch.float16
patch_torch_functions : False
keep_batchnorm_fp32 : True
master_weights : True
loss_scale : 1.0
Warning: multi_tensor_applier fused unscale kernel is unavailable, possibly because apex was installed without --cuda_ext --cpp_ext. Using Python fallback. Original ImportError was: ModuleNotFoundError("No module named 'amp_C'",)
import torch.distributed as dist
dist.init_process_group('nccl',init_method='tcp://localhost:12578',world_size=2, rank = rank)
from torch.nn.parallel import DistributedDataParallel as DDP
model = DDP(model, device_ids=[device_id],output_device=gpu, find_unused_parameters = True)
# dist.destroy_process_group()
model.zero_grad()
optimizer.zero_grad()
input = input_cpu.to(gpu)
for i in range(4):
if i%2 ==0:
model.require_backward_grad_sync = False
else:
model.require_backward_grad_sync = True
#_amp_state.loss_scalers[0]._loss_scale = 10+i
print(f'\n\n****step = {i+1}, sync = {model.require_backward_grad_sync}')
print(f'loss scale = {_amp_state.loss_scalers[0].loss_scale()}')
fp_16train_step(model,input)
print('\nmodel param')
print_params(model)
print('\nmaster param')
for param in optimizer.param_groups[0]['params']:
print(param,param.grad,param.dtype)
if i%2 !=0:
print('stepping optimizer')
optimizer.step()
optimizer.zero_grad()
Process 1
****step = 1, sync = False
loss scale = 1.0
model param
module.weight = Parameter containing:
tensor([[0.1121]], device='cuda:0', dtype=torch.float16, requires_grad=True), grad = tensor([[1.]], device='cuda:0', dtype=torch.float16)
module.bias = Parameter containing:
tensor([0.5967], device='cuda:0', dtype=torch.float16, requires_grad=True), grad = tensor([1.], device='cuda:0', dtype=torch.float16)
master param
tensor([[0.1121]], device='cuda:0', requires_grad=True) tensor([[1.]], device='cuda:0') torch.float32
tensor([0.5967], device='cuda:0', requires_grad=True) tensor([1.], device='cuda:0') torch.float32
****step = 2, sync = True
loss scale = 1.0
model param
module.weight = Parameter containing:
tensor([[0.1121]], device='cuda:0', dtype=torch.float16, requires_grad=True), grad = tensor([[1.5000]], device='cuda:0', dtype=torch.float16)
module.bias = Parameter containing:
tensor([0.5967], device='cuda:0', dtype=torch.float16, requires_grad=True), grad = tensor([1.], device='cuda:0', dtype=torch.float16)
master param
tensor([[0.1121]], device='cuda:0', requires_grad=True) tensor([[2.5000]], device='cuda:0') torch.float32
tensor([0.5967], device='cuda:0', requires_grad=True) tensor([2.], device='cuda:0') torch.float32
stepping optimizer
****step = 3, sync = False
loss scale = 1.0
model param
module.weight = Parameter containing:
tensor([[-0.1379]], device='cuda:0', dtype=torch.float16, requires_grad=True), grad = tensor([[1.]], device='cuda:0', dtype=torch.float16)
module.bias = Parameter containing:
tensor([0.3967], device='cuda:0', dtype=torch.float16, requires_grad=True), grad = tensor([1.], device='cuda:0', dtype=torch.float16)
master param
tensor([[-0.1379]], device='cuda:0', requires_grad=True) tensor([[1.]], device='cuda:0') torch.float32
tensor([0.3967], device='cuda:0', requires_grad=True) tensor([1.], device='cuda:0') torch.float32
****step = 4, sync = True
loss scale = 1.0
model param
module.weight = Parameter containing:
tensor([[-0.1379]], device='cuda:0', dtype=torch.float16, requires_grad=True), grad = tensor([[1.5000]], device='cuda:0', dtype=torch.float16)
module.bias = Parameter containing:
tensor([0.3967], device='cuda:0', dtype=torch.float16, requires_grad=True), grad = tensor([1.], device='cuda:0', dtype=torch.float16)
master param
tensor([[-0.1379]], device='cuda:0', requires_grad=True) tensor([[2.5000]], device='cuda:0') torch.float32
tensor([0.3967], device='cuda:0', requires_grad=True) tensor([2.], device='cuda:0') torch.float32
stepping optimizer
Process 2
****step = 1, sync = False
loss scale = 1.0
model param
module.weight = Parameter containing:
tensor([[0.1121]], device='cuda:1', dtype=torch.float16, requires_grad=True), grad = tensor([[2.]], device='cuda:1', dtype=torch.float16)
module.bias = Parameter containing:
tensor([0.5967], device='cuda:1', dtype=torch.float16, requires_grad=True), grad = tensor([1.], device='cuda:1', dtype=torch.float16)
master param
tensor([[0.1121]], device='cuda:1', requires_grad=True) tensor([[2.]], device='cuda:1') torch.float32
tensor([0.5967], device='cuda:1', requires_grad=True) tensor([1.], device='cuda:1') torch.float32
****step = 2, sync = True
loss scale = 1.0
model param
module.weight = Parameter containing:
tensor([[0.1121]], device='cuda:1', dtype=torch.float16, requires_grad=True), grad = tensor([[1.5000]], device='cuda:1', dtype=torch.float16)
module.bias = Parameter containing:
tensor([0.5967], device='cuda:1', dtype=torch.float16, requires_grad=True), grad = tensor([1.], device='cuda:1', dtype=torch.float16)
master param
tensor([[0.1121]], device='cuda:1', requires_grad=True) tensor([[3.5000]], device='cuda:1') torch.float32
tensor([0.5967], device='cuda:1', requires_grad=True) tensor([2.], device='cuda:1') torch.float32
stepping optimizer
****step = 3, sync = False
loss scale = 1.0
model param
module.weight = Parameter containing:
tensor([[-0.2379]], device='cuda:1', dtype=torch.float16, requires_grad=True), grad = tensor([[2.]], device='cuda:1', dtype=torch.float16)
module.bias = Parameter containing:
tensor([0.3967], device='cuda:1', dtype=torch.float16, requires_grad=True), grad = tensor([1.], device='cuda:1', dtype=torch.float16)
master param
tensor([[-0.2379]], device='cuda:1', requires_grad=True) tensor([[2.]], device='cuda:1') torch.float32
tensor([0.3967], device='cuda:1', requires_grad=True) tensor([1.], device='cuda:1') torch.float32
****step = 4, sync = True
loss scale = 1.0
model param
module.weight = Parameter containing:
tensor([[-0.2379]], device='cuda:1', dtype=torch.float16, requires_grad=True), grad = tensor([[1.5000]], device='cuda:1', dtype=torch.float16)
module.bias = Parameter containing:
tensor([0.3967], device='cuda:1', dtype=torch.float16, requires_grad=True), grad = tensor([1.], device='cuda:1', dtype=torch.float16)
master param
tensor([[-0.2379]], device='cuda:1', requires_grad=True) tensor([[3.5000]], device='cuda:1') torch.float32
tensor([0.3967], device='cuda:1', requires_grad=True) tensor([2.], device='cuda:1') torch.float32
stepping optimizer
Code changes to solve the issue
def fp_16train_step(model, input, reduction_disabled):
out = model(input)
loss = out.mean()
with amp.scale_loss(loss,optimizer,delay_unscale=reduction_disabled) as scaled_loss:
scaled_loss.backward()
model.zero_grad()
optimizer.zero_grad()
input = input_cpu.to(gpu)
ga = 3
for i in range(6):
reduction_disabled = False if (i+1)%ga ==0 else True
model.require_backward_grad_sync = not reduction_disabled
#_amp_state.loss_scalers[0]._loss_scale = 10+i
print(f'\n\n****step = {i+1}, sync = {model.require_backward_grad_sync}')
print(f'loss scale = {_amp_state.loss_scalers[0].loss_scale()}')
fp_16train_step(model,input, reduction_disabled)
print('\nmodel param')
print_params(model)
print('\nmaster param')
for param in optimizer.param_groups[0]['params']:
print(param,param.grad,param.dtype)
if not reduction_disabled:
print('\nstepping optimizer')
optimizer.step()
optimizer.zero_grad()
Process 1
****step = 1, sync = False
loss scale = 1.0
model param
module.weight = Parameter containing:
tensor([[0.1121]], device='cuda:0', dtype=torch.float16, requires_grad=True), grad = tensor([[1.]], device='cuda:0', dtype=torch.float16)
module.bias = Parameter containing:
tensor([0.5967], device='cuda:0', dtype=torch.float16, requires_grad=True), grad = tensor([1.], device='cuda:0', dtype=torch.float16)
master param
tensor([[0.1121]], device='cuda:0', requires_grad=True) None torch.float32
tensor([0.5967], device='cuda:0', requires_grad=True) None torch.float32
****step = 2, sync = False
loss scale = 1.0
model param
module.weight = Parameter containing:
tensor([[0.1121]], device='cuda:0', dtype=torch.float16, requires_grad=True), grad = tensor([[2.]], device='cuda:0', dtype=torch.float16)
module.bias = Parameter containing:
tensor([0.5967], device='cuda:0', dtype=torch.float16, requires_grad=True), grad = tensor([2.], device='cuda:0', dtype=torch.float16)
master param
tensor([[0.1121]], device='cuda:0', requires_grad=True) None torch.float32
tensor([0.5967], device='cuda:0', requires_grad=True) None torch.float32
****step = 3, sync = True
loss scale = 1.0
model param
module.weight = Parameter containing:
tensor([[0.1121]], device='cuda:0', dtype=torch.float16, requires_grad=True), grad = tensor([[4.5000]], device='cuda:0', dtype=torch.float16)
module.bias = Parameter containing:
tensor([0.5967], device='cuda:0', dtype=torch.float16, requires_grad=True), grad = tensor([3.], device='cuda:0', dtype=torch.float16)
master param
tensor([[0.1121]], device='cuda:0', requires_grad=True) tensor([[4.5000]], device='cuda:0') torch.float32
tensor([0.5967], device='cuda:0', requires_grad=True) tensor([3.], device='cuda:0') torch.float32
stepping optimizer
****step = 4, sync = False
loss scale = 1.0
model param
module.weight = Parameter containing:
tensor([[-0.3379]], device='cuda:0', dtype=torch.float16, requires_grad=True), grad = tensor([[1.]], device='cuda:0', dtype=torch.float16)
module.bias = Parameter containing:
tensor([0.2966], device='cuda:0', dtype=torch.float16, requires_grad=True), grad = tensor([1.], device='cuda:0', dtype=torch.float16)
master param
tensor([[-0.3379]], device='cuda:0', requires_grad=True) None torch.float32
tensor([0.2967], device='cuda:0', requires_grad=True) None torch.float32
Process 2
****step = 1, sync = False
loss scale = 1.0
model param
module.weight = Parameter containing:
tensor([[0.1121]], device='cuda:1', dtype=torch.float16, requires_grad=True), grad = tensor([[2.]], device='cuda:1', dtype=torch.float16)
module.bias = Parameter containing:
tensor([0.5967], device='cuda:1', dtype=torch.float16, requires_grad=True), grad = tensor([1.], device='cuda:1', dtype=torch.float16)
master param
tensor([[0.1121]], device='cuda:1', requires_grad=True) None torch.float32
tensor([0.5967], device='cuda:1', requires_grad=True) None torch.float32
****step = 2, sync = False
loss scale = 1.0
model param
module.weight = Parameter containing:
tensor([[0.1121]], device='cuda:1', dtype=torch.float16, requires_grad=True), grad = tensor([[4.]], device='cuda:1', dtype=torch.float16)
module.bias = Parameter containing:
tensor([0.5967], device='cuda:1', dtype=torch.float16, requires_grad=True), grad = tensor([2.], device='cuda:1', dtype=torch.float16)
master param
tensor([[0.1121]], device='cuda:1', requires_grad=True) None torch.float32
tensor([0.5967], device='cuda:1', requires_grad=True) None torch.float32
****step = 3, sync = True
loss scale = 1.0
model param
module.weight = Parameter containing:
tensor([[0.1121]], device='cuda:1', dtype=torch.float16, requires_grad=True), grad = tensor([[4.5000]], device='cuda:1', dtype=torch.float16)
module.bias = Parameter containing:
tensor([0.5967], device='cuda:1', dtype=torch.float16, requires_grad=True), grad = tensor([3.], device='cuda:1', dtype=torch.float16)
master param
tensor([[0.1121]], device='cuda:1', requires_grad=True) tensor([[4.5000]], device='cuda:1') torch.float32
tensor([0.5967], device='cuda:1', requires_grad=True) tensor([3.], device='cuda:1') torch.float32
stepping optimizer
****step = 4, sync = False
loss scale = 1.0
model param
module.weight = Parameter containing:
tensor([[-0.3379]], device='cuda:1', dtype=torch.float16, requires_grad=True), grad = tensor([[2.]], device='cuda:1', dtype=torch.float16)
module.bias = Parameter containing:
tensor([0.2966], device='cuda:1', dtype=torch.float16, requires_grad=True), grad = tensor([1.], device='cuda:1', dtype=torch.float16)
master param
tensor([[-0.3379]], device='cuda:1', requires_grad=True) None torch.float32
tensor([0.2967], device='cuda:1', requires_grad=True) None torch.float32