NVIDIA mixed precission training
Amp: Automatic Mixed Precision
The Volta generation of GPUs introduces tensor cores, which provide 8x more throughput than single precision math pipelines. NVIDIA tensor cores provide hardware acceleration for mixed precision training. Mixed precision methods combine the use of different numerical formats in one computational workload.
There are numerous benefits to using numerical formats with lower precision than 32-bit floating point.
-
They require less memory, enabling the training and deployment of larger neural networks.
-
They require less memory bandwidth, thereby speeding up data transfer operations.
-
Math operations run much faster in reduced precision, especially on GPUs with Tensor Core support for that precision.
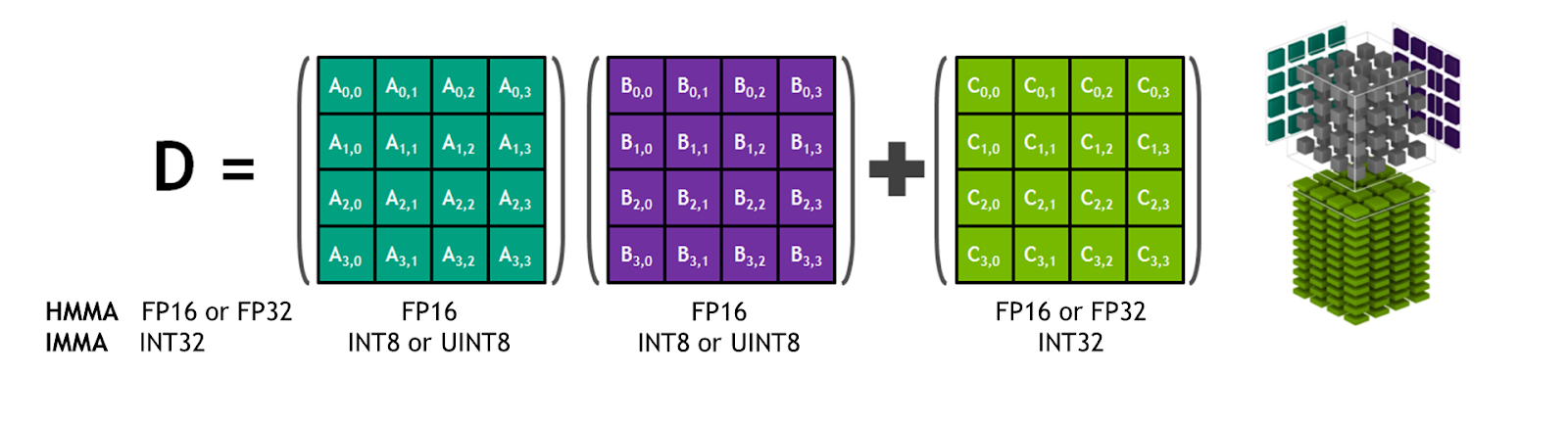
Tensor Cores provide fast matrix multiply-add with FP16 input and FP32 compute capabilities.
Mixed precision training achieves all these benefits while ensuring that no task-specific accuracy is lost compared to full precision training. It does so by identifying the steps that require full precision and using 32-bit floating point for only those steps while using 16-bit floating point everywhere else.
https://github.com/NVIDIA/apex
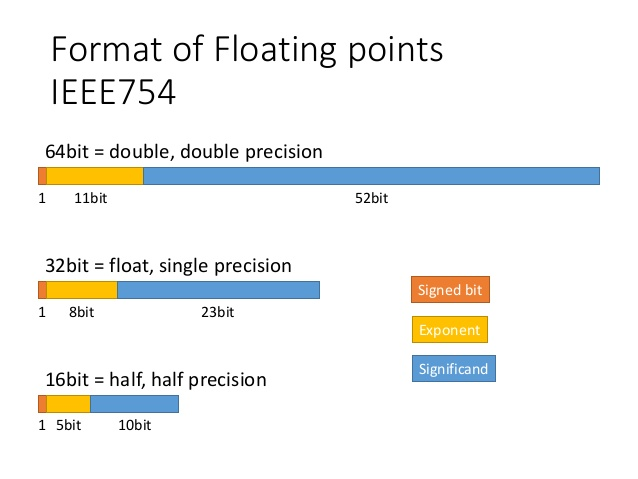
How single precission is computed?
https://www.youtube.com/watch?v=tx-M_rqhuUA
https://www.youtube.com/watch?v=4DfXdJdaNYs
NVIDIA blogs and video lectures
Using Tensor Cores for Mixed-Precision Scientific Computing
Video Series: Mixed-Precision Training Techniques Using Tensor Cores for Deep Learning
https://docs.nvidia.com/deeplearning/sdk/mixed-precision-training/index.html
Apex
Official doc: NVIDIA Apex: Tools for Easy Mixed-Precision Training in PyTorch
In brief, the methodology is:
- FP32 master parameters to store and accumulate updates.
- Loss scaling to prevent underflowing gradients.
- A few operations (e.g. large reductions) converted to FP32.
- Everything else (the majority of the network) executed in FP16.
Detailed Steps:
- Make an FP16 copy of the weights Forward propagate using FP16 weights and activations
- Multiply the resulting loss by the scale factor S
- Backward propagate using FP16 weights, activations, and their gradients
- Multiply the weight gradients by 1/S
- Optionally process the weight gradients (gradient clipping, weight decay, etc.)
- Update the master copy of weights in FP32
What does PyTorch have?
- Calling .half() on a module converts its parameters to FP16, and calling .half() on a tensor converts its data to FP16. Any operations performed on such modules or tensors will be carried out using fast FP16 arithmetic.
- Strong built-in support for NVIDIA math libraries (cuBLAS and cuDNN). These libraries use Tensor Cores to perform GEMMs (e.g., fully connected layers) and convolutions on FP16 data. A GEMM with dimensions [M, K] x [K, N] -> [M, N], allows cuBLAS to use Tensor Cores, assuming that M, K, and N be multiples of 8.
What does Apex do?
Apex is a lightweight PyTorch extension that contains two alternative tools for mixed-precision training:
-
Amp: automatic mixed-precision
A library for automatically enabling all the steps of mixed-precision training.
- Pros:
- Simplicity.
- Performs relatively low-level modifications to the running model.
- You need not worry about mixed types when writing or running your model training script.
- Cons
- Reduced control.
- Models that use PyTorch in less common ways may find Amp’s assumptions don’t fit as well. However, hooks exist to modify those assumptions as needed.
- Pros:
-
A class that wraps an existing PyTorch optimizer instance. FP16_Optimizerhandles master weights and loss scaling automatically, and can be implemented in an existing half-precision training script by changing only two lines.
- Pros:
- Control.
- It operates at the user-API level of PyTorch and so can be easily adapted to unusual or sophisticated applications.
- Cons
- Slightly less simplicity than Amp
- The top-level script is responsible for specifying precision of operations internal to the model.
- Pros:
We recommend that anyone getting started with mixed-precision training start with Amp.
Those seeking more control or who find Amp’s restrictions limiting should look at FP16_Optimizer.
Paper on mixed precission training
FAQ
-
What is apex.parallel.DDP
apex.parallel.DistributedDataParallel is a module wrapper, similar to torch.nn.parallel.DistributedDataParallel. It enables convenient multiprocess distributed training, optimized for NVIDIA’s NCCL communication library.
-
What is Amp apex.amp is a tool to enable mixed precision training by changing only 3 lines of your script. Users can easily experiment with different pure and mixed precision training modes by supplying different flags to amp.initialize.
AMP API documentation: https://nvidia.github.io/apex/amp.html
Github source: https://github.com/NVIDIA/apex
Installation Instructions (Linux)
$ git clone https://github.com/NVIDIA/apex
$ cd apex
$ pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
Example
# Declare model and optimizer as usual, with default (FP32) precision
model = torch.nn.Linear(D_in, D_out).cuda()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
# Allow Amp to perform casts as required by the opt_level
model, optimizer = amp.initialize(model, optimizer, opt_level="O1")
...
# loss.backward() becomes:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
...
initialize
https://nvidia.github.io/apex/amp.html#apex.amp.initialize
model, optimizer = amp.initialize(model, optimizer, opt_level="O1")
Initialize your models, optimizers, and the Torch tensor and functional namespace according to the chosen opt_level and overridden properties, if any.
amp.initialize should be called after you have finished constructing your model(s) and optimizer(s), but before you send your model through any DistributedDataParallel wrapper. See Distributed training in the Imagenet example.
Does this mean optimizer before horovod should be passed or after?
scale_loss
For more info on what happens in scale_loss, check out https://nvidia.github.io/apex/amp.html#apex.amp.scale_loss On context manager entrance, creates scaled_loss = (loss.float())*current loss scale. scaled_loss is yielded so that the user can call scaled_loss.backward():
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
On context manager exit (if delay_unscale=False), the gradients are checked for infs/NaNs and unscaled, so that optimizer.step() can be called.
Note
If Amp is using explicit FP32 master params (which is the default for opt_level=O2, and can also be manually enabled by supplying master_weights=True to amp.initialize) any FP16 gradients are copied to FP32 master gradients before being unscaled. optimizer.step() will then apply the unscaled master gradients to the master params.
Warning
If Amp is using explicit FP32 master params, only the FP32 master gradients will be unscaled. The direct .grad attributes of any FP16 model params will remain scaled after context manager exit. This subtlety affects gradient clipping. See “Gradient clipping” under Advanced Amp Usage for best practices.
FP16 usage example
https://github.com/NVIDIA/apex/blob/master/examples/imagenet/main_amp.py
# For distributed training, wrap the model with apex.parallel.DistributedDataParallel.
# This must be done AFTER the call to amp.initialize. If model = DDP(model) is called
# before model, ... = amp.initialize(model, ...), the call to amp.initialize may alter
# the types of model's parameters in a way that disrupts or destroys DDP's allreduce hooks.