PyTorch distributed communication - Multi node
WRITING DISTRIBUTED APPLICATIONS WITH PYTORCH
The distributed package included in PyTorch (i.e., torch.distributed) enables researchers and practitioners to easily parallelize their computations across processes and clusters of machines. To do so, it leverages the messaging passing semantics allowing each process to communicate data to any of the other processes.
I booted two data science virtual machines in Azure. Copied their IP adresses and in my browser opened https://machine-ip:8000 to open jupyter hub.
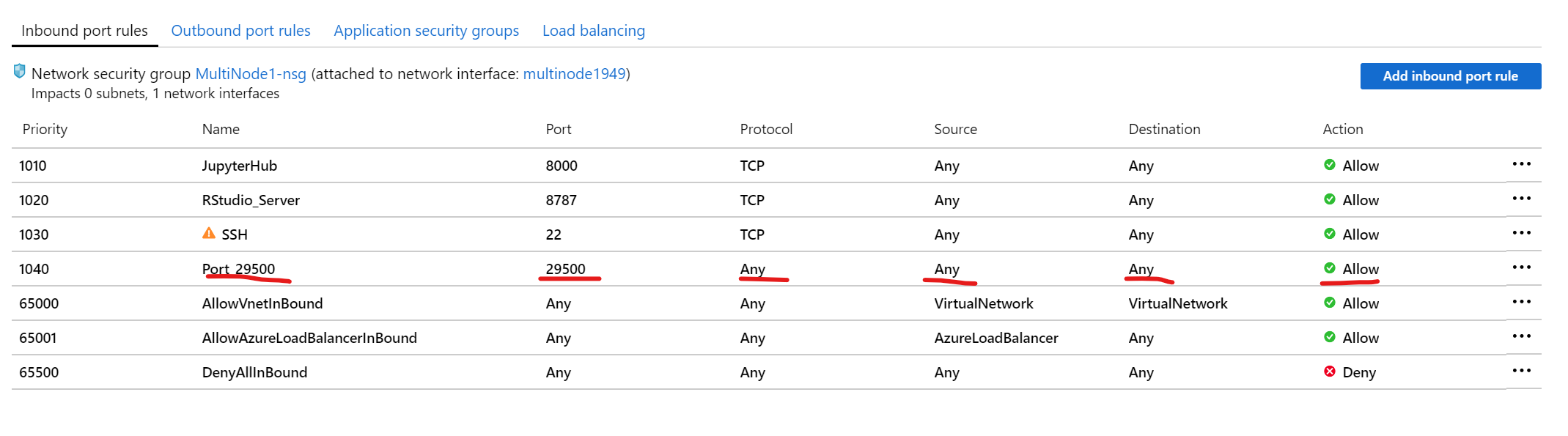
Also for running multinode distributed experiments, few things should be taken care while booting the machines in Azure.
-
Machines need to be in same resource group

-
One of the machines which will be master should have a port open for incoming connections.
Node 1
import torch
import socket
torch.distributed.is_gloo_available()
print(socket.gethostname())
krishan-standard-machine
process groups
import os
import torch.distributed as dist
from torch.multiprocessing import Process
from time import sleep
import datetime
def init_processes(rank, size, fn, backend='gloo'):
""" Initialize the distributed environment. """
#Alternate way to provice rank 0 IP and open port
#os.environ['MASTER_ADDR'] = '52.250.110.24'
#os.environ['MASTER_PORT'] = '29500'
print('{} : started process for rank : {}'.format(os.getpid(),rank))
#Remove init_method if initializing through environment variable
dist.init_process_group(backend = backend, \
init_method='tcp://52.250.110.24:29500',\ #Provide rank 0 IP and open port
rank=rank,\
world_size=size,\
timeout=datetime.timedelta(0,seconds = 20))
#dist.init_process_group(backend, rank=rank, world_size=size)
fn(rank, size)
def startprocesses(ranks, size, fn):
processes = []
for rank in ranks:
p = Process(target=init_processes, args=(rank, size, fn))
p.start()
processes.append(p)
for p in processes:
p.join()
print('finished')
The above script spawns len(ranks) processes who will each setup the distributed environment, initialize the process group (dist.init_process_group), and finally execute the given function.
Let’s have a look at the init_processes function. It ensures that every process will be able to coordinate through a master, using the same ip address and port. Note that we used the gloo backend, but we could have used MPI or NCCL instead.
dist.init_process_group essentially allows processes to communicate with each other by sharing their locations.
1. A simple function
def run(rank, size):
""" Distributed function. """
print('{} :Inside rank {}, total processes = {}'\
.format (os.getpid(),rank,size))
#sleep(5)
print('{} exiting process'.format(os.getpid()))
Test in same node
startprocesses([0,1],2,run)
9536 : started process for rank : 0
9539 : started process for rank : 1
9539 :Inside rank 1, total processes = 2
9536 :Inside rank 0, total processes = 2
9536 exiting process
9539 exiting process
finished
Test with Multi Node
startprocesses([0,1],3,run)
28940 : started process for rank : 0
28941 : started process for rank : 1
28941 :Inside rank 1, total processes = 3
28940 :Inside rank 0, total processes = 3
28941 exiting process
28940 exiting process
finished
There are multiple ways to initialize distributed communication using dist.init_process_group(). I have shown two of them.
Make sure Rank 0 is always the master node. Otherwise the communication will timeout. This is both experimental and mentioned in pytorch docs.
2. Send and recieve data between processes
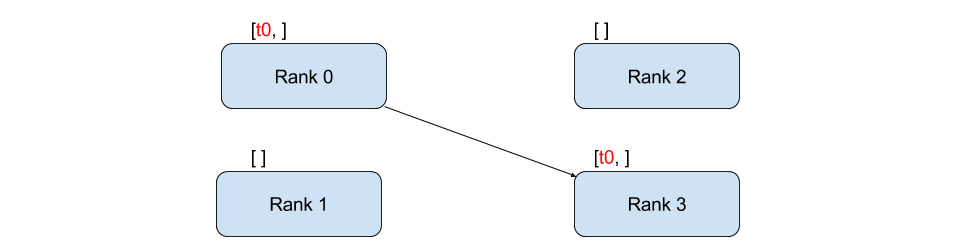
def sendreceive(rank, size):
tensor = torch.zeros(3)
req = None
print('{} : Inside Rank {} '\
.format(os.getpid(), rank))
if rank == 0:
tensor[1] = 1
req = dist.isend(tensor, dst=3)
req.wait()
elif rank ==3:
req = dist.irecv(tensor, src=0)
req.wait()
print('{} : Rank {} has data {}'\
.format(os.getpid(), rank,tensor))
startprocesses([0,1,2],4,sendreceive)
29837 : started process for rank : 0
29840 : started process for rank : 1
29844 : started process for rank : 2
29840 : Inside Rank 1
29844 : Inside Rank 2
29844 : Rank 2 has data tensor([0., 0., 0.])
29840 : Rank 1 has data tensor([0., 0., 0.])
29837 : Inside Rank 0
29837 : Rank 0 has data tensor([0., 1., 0.])
finished
3. All Reduce
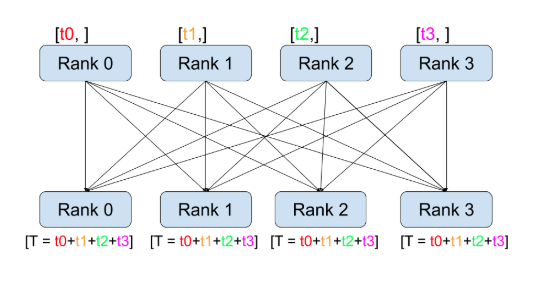 As opposed to point-to-point communcation, collectives allow for communication patterns across all processes in a group. A group is a subset of all our processes. To create a group, we can pass a list of ranks to dist.new_group(group). By default, collectives are executed on the all processes*, also known as the world. For example, in order to obtain the sum of all tensors at all processes, we can use the dist.all_reduce(tensor, op, group) collective.
As opposed to point-to-point communcation, collectives allow for communication patterns across all processes in a group. A group is a subset of all our processes. To create a group, we can pass a list of ranks to dist.new_group(group). By default, collectives are executed on the all processes*, also known as the world. For example, in order to obtain the sum of all tensors at all processes, we can use the dist.all_reduce(tensor, op, group) collective.
dist.reduce(tensor, dst, op, group): Applies op to all tensor and stores the result in dst.
dist.all_reduce(tensor, op, group): Same as reduce, but the result is stored in all processes.
def all_reduce(rank, size):
group = dist.new_group([0,1,2])
tensor = torch.ones(3)
print('{} : Before allreducce: Rank {} has data {}'\
.format(os.getpid(), rank,tensor))
dist.all_reduce(tensor, op = dist.ReduceOp.SUM, group= group)
print('{} : After allreduce: Rank {} has data {}'\
.format(os.getpid(), rank,tensor))
startprocesses([0],3,all_reduce)
30223 : started process for rank : 0
30223 : Before allreducce: Rank 0 has data tensor([1., 1., 1.])
30223 : After allreduce: Rank 0 has data tensor([3., 3., 3.])
finished
4. Broadcast
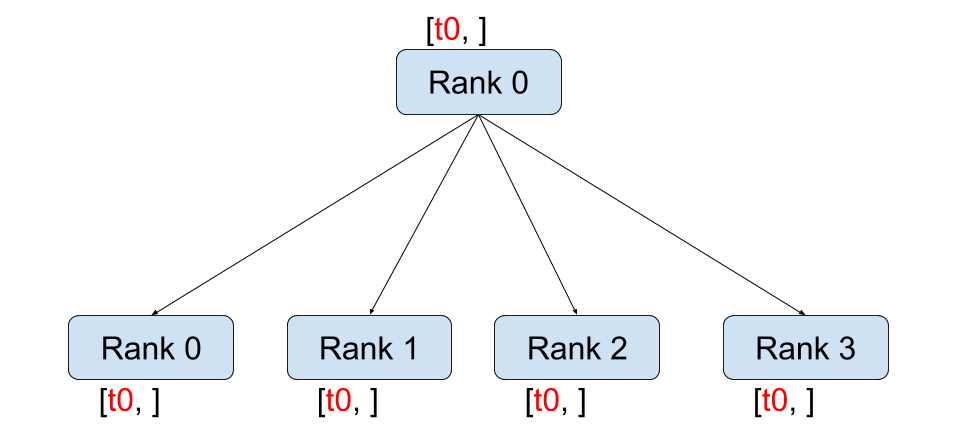
def broadcast(rank, size):
group = dist.new_group([0,1])
if rank == 0:
tensor = torch.zeros(3)
else:
tensor = torch.ones(3)
print('{} : Before braodcasting: Rank {} has data {}'\
.format(os.getpid(), rank,tensor))
dist.broadcast(tensor, src = 0, group= group)
print('{} : After braodcasting: Rank {} has data {}'\
.format(os.getpid(), rank,tensor))
startprocesses([0,1],2,broadcast)
29970 : started process for rank : 0
29973 : started process for rank : 1
29973 : Before braodcasting: Rank 1 has data tensor([1., 1., 1.])
29970 : Before braodcasting: Rank 0 has data tensor([0., 0., 0.])
29970 : After braodcasting: Rank 0 has data tensor([0., 0., 0.])
29973 : After braodcasting: Rank 1 has data tensor([0., 0., 0.])
finished
Note
for _address in use _ errors, check which process is using the port and kill that.
!netstat -tulpn| grep 29500
Timeout is set to 20 seconds. Run corresponding startprocesses(…) command in node 2 within 20 seconds to avoid timeouts.
If still getting timeout errors, that means the arguments to startprocesses(…) are not correct. Make sure sum of len(ranks) from all nodes is equal to size. Provide same size value from all nodes
Node 2
import os
import torch.distributed as dist
from torch.multiprocessing import Process
from time import sleep
import datetime
import torch
import socket
import torch
def init_processes(rank, size, fn, backend='gloo'):
""" Initialize the distributed environment. """
#alternate way to provice rank 0 IP
#os.environ['MASTER_ADDR'] = '12.0.0.1'
#os.environ['MASTER_PORT'] = '29500'
#provide rank 0 IP using init_method
print('{} : started process for rank : {}'.format(os.getpid(),rank))
dist.init_process_group(backend = backend, \
init_method='tcp://52.250.110.24:29500',\
rank=rank,\
world_size=size,\
timeout=datetime.timedelta(0,seconds = 20))
#dist.init_process_group(backend, rank=rank, world_size=size)
fn(rank, size)
def startprocesses(ranks, size, fn):
processes = []
for rank in ranks:
p = Process(target=init_processes, args=(rank, size, fn))
p.start()
processes.append(p)
for p in processes:
p.join()
print('finished')
def run(rank, size):
""" Distributed function. """
print('{} :Inside rank {}, total processes = {}'\
.format (os.getpid(),rank,size))
sleep(5)
print('{} exiting process'.format(os.getpid()))
startprocesses([2],3,run)
12613 : started process for rank : 2
12613 :Inside rank 2, total processes = 3
12613 exiting process
finished
def sendreceive(rank, size):
tensor = torch.zeros(3)
reqs = []
if rank == 0:
print('{} : Inside Rank {} '\
.format(os.getpid(), rank))
tensor[1] = 1
for r in range(1, size):
req = dist.isend(tensor, dst=r)
reqs.append(req)
else:
req = dist.irecv(tensor, src=0)
reqs.append(req)
for req in reqs:
req.wait()
print('{} : Rank {} has data {}'\
.format(os.getpid(), rank,tensor))
startprocesses([2,3],4,sendreceive)
12466 : started process for rank : 2
12469 : started process for rank : 3
12469 : Rank 3 has data tensor([0., 1., 0.])
12466 : Rank 2 has data tensor([0., 1., 0.])
finished
def all_reduce(rank, size):
group = dist.new_group([0,1,2])
tensor = torch.ones(3)
print('{} : Before allreducce: Rank {} has data {}'\
.format(os.getpid(), rank,tensor))
dist.all_reduce(tensor, op = dist.ReduceOp.SUM, group= group)
print('{} : After allreduce: Rank {} has data {}'\
.format(os.getpid(), rank,tensor))
startprocesses([1,2],3,all_reduce)
13565 : started process for rank : 1
13568 : started process for rank : 2
13565 : Before allreducce: Rank 1 has data tensor([1., 1., 1.])
13568 : Before allreducce: Rank 2 has data tensor([1., 1., 1.])
13565 : After allreduce: Rank 1 has data tensor([3., 3., 3.])
13568 : After allreduce: Rank 2 has data tensor([3., 3., 3.])
finished