LAMB paper summary
Previous LR scaling with batch size
- Simple large batch training Training with extremely large batch was difficult. The researchers needed to carefully tune training hyper-parameters, like learning rate and momentum
- Increase the LR (learning rate) by √ b when batch size is scaled by b . Paper optimization instability due to high learning rate.
- Learning rate warm-up strategy empirical study shows that learning rate scaling heuristics with the batch size do not hold across all problems or across all batch sizes
- Adaptive learning rate layer wise - Lars and LAMB A theoretical understanding of the adaptation employed in LARS is largely missing
LAMB
Adaptive layerwise optimization
Notations: xt are parameters and st are samples
Loss function
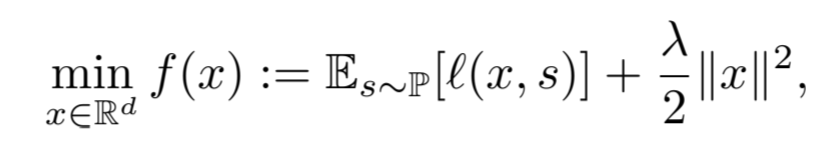
Simple SGD
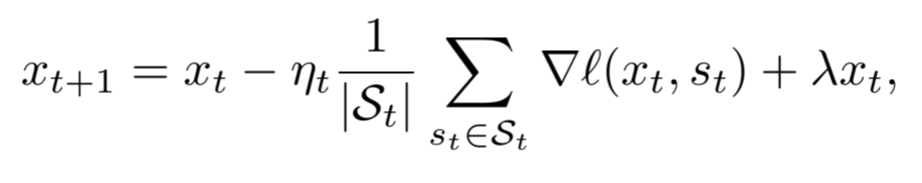
where St is set of b random samples drawn from the distribution P. This can be simplified to
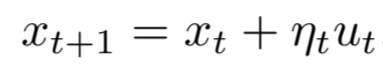
General Strategy
For adaptive layerwise learning
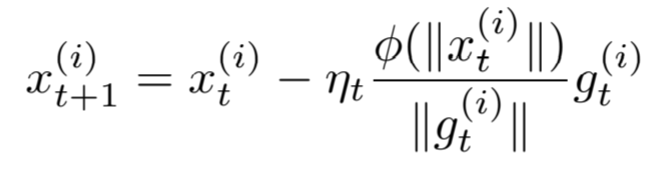
for all layers i∈[h] and where x^(i)^ and g^(i)^ are the parameters and the gradients of the i th layer at time step t.
the paper proposes the following two changes to the update for large batch settings:
- The update is normalized to unit l2-norm. This is ensured by modifying the update to the form u~t~/|u~t~|. Throughout this paper, such a normalization is done layerwise
- The learning rate is scaled by φ(|x~t~|) for some function φ. Similar to the normalization, such a scaling is done layerwise.
Benefits:
- such a normalization(gt/|g~t~|) provides robustness to exploding gradients (where the gradient can be arbitrarily large) and plateaus (where the gradient can be arbitrarily small).Normalization of this form essentially ignores the size of the gradient (adding a bit of bias) and is particularly useful in large batch settings where the direction of the gradient is largely preserved.
- The scaling term involving φ ensures that the norm of the update is of the same order as that of the parameter. We found that this typically ensures faster convergence in deep neural networks
Both LARS and LAMB are based on this general strategy.

LARS uses momentum optimizer as the base while LAMB uses ADAM optimizer as the base algorithm for general strategy.
Unlike LARS, the adaptivity of LAMB is two-fold:
- per dimension normalization with respect to the square root of the second moment used in ADAM and
- layerwise normalization obtained due to layerwise adaptivity. (How? : Lars also normalizes layerwise)
Experiments and results:
BERT
- β1 and β2 are set to 0.9 and 0.999
- Polynomial decay with the power of 1.0 (nt = n0×(1−t/T))
- did not tune the hyperparameters of LAMB while increasing the batch size
- We use the square root of LR scaling rule Krizhevsky (2014) to automatically adjust learning rate and linear-epoch warmup scheduling You et al. (2019).
- We use TPUv3 in all the experiments.
- To train BERT, Devlin et al. (2018) first train the model for 900k iterations using sequence length of 128 and then switch to sequence length of 512 for the last 100k iterations.
- The F1 score on SQuAD-v1 is used as the accuracy metric in our experiments. The baseline BERT model 2 achieves a F1 score of 90.395. We report a F1 score of 91.345 , which is the score obtained for the untuned version
- To ensure a fair comparison, we follow the same SQuAD fine-tune procedure of (Devlin et al., 2018) without modifying any configuration (including number of epochs and hyperparameters).
- By just slightly changing the learning rate in the fine-tune stage, we can obtain a higher F1 score of 91.688 for the batch size of 16K using LAMB.
- Two different training choices for training BERT using LAMB
- Regular Training using LAMB
- Maintain the same training procedure as the baseline except for changing the pre-training optimizer to LAMB.We run with the same number of epochs as the baseline but with batch size scaled from 512 to 32K.
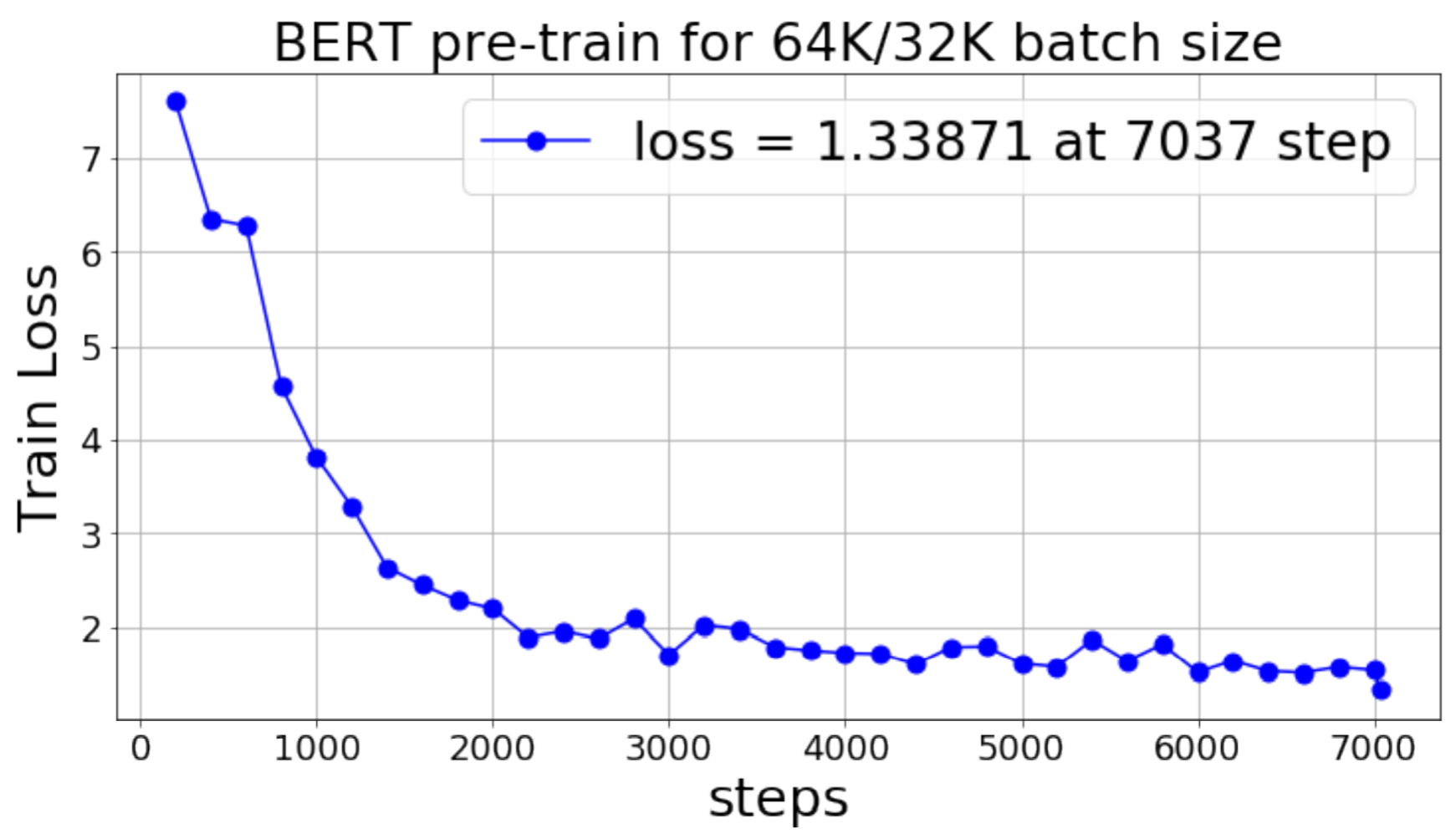
- By using the LAMB optimizer, we are able to achieve a F1 score of 91.460 in 15625 iterations for a batch size of 32768 (14063 iterations for sequence length 128 and 1562 iterations for sequence length 512). With 32K batch size, we reduce BERT pre-training time from 3 days to around 100 minutes.
- We achieved 76.7% scaling efficiency
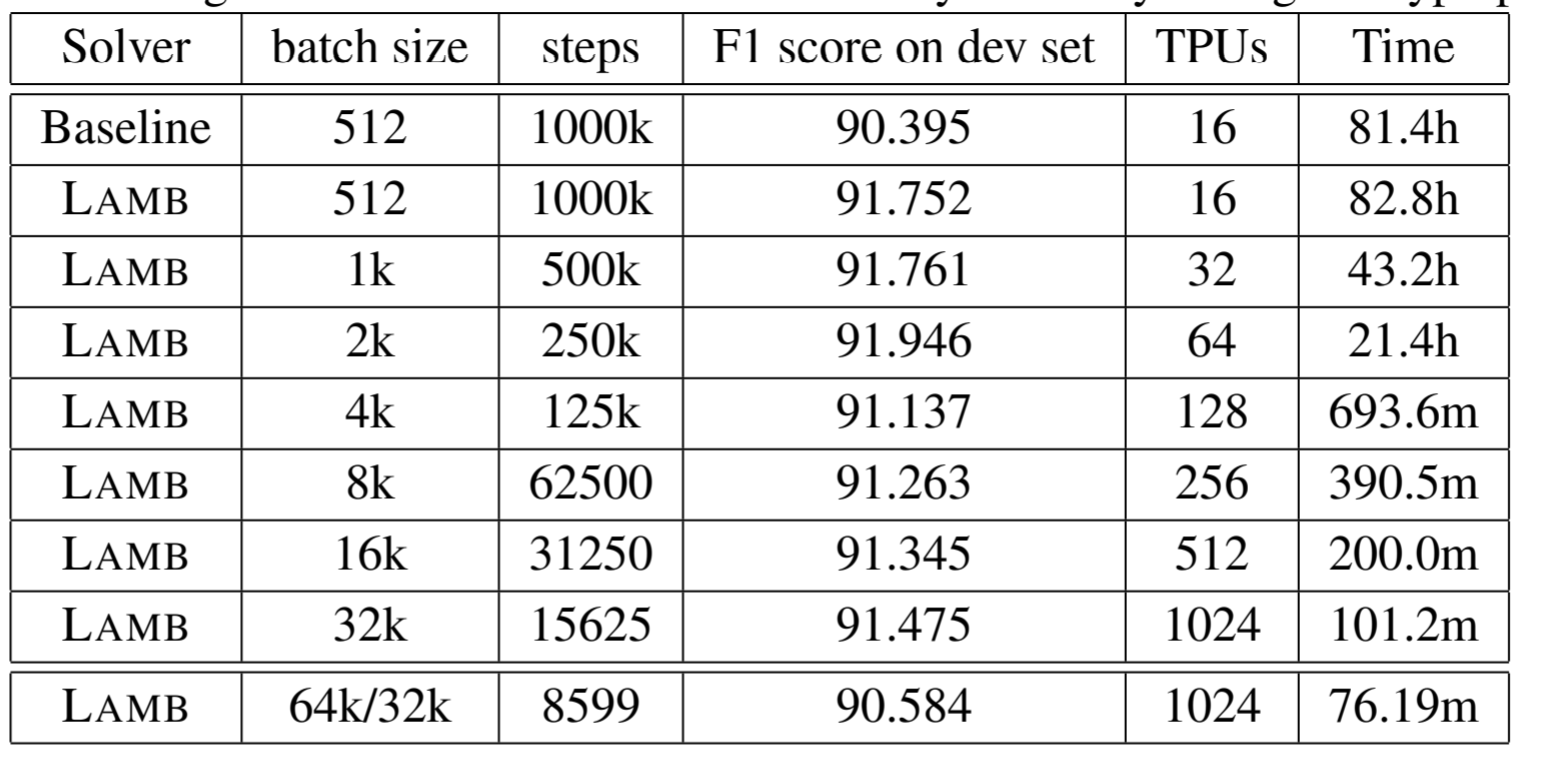
- Mixed-Batch Training using LAMB
- BERT pre-training involves two stages: the first 9/10 of the total epochs use a sequence length of 128, while the last 1/10 of the total epochs use a sequence length of 512.
- we increase the batch size to 65536 for this stage.
- we are able to make full utilization of the hardware resources throughout the training procedure.
- Instead of decaying the learning rate at the second stage, we ramp up the learning rate from zero again in the second stage (re-warm-up). As with the first stage, we decay the learning rate after the re-warm-up phase.
- Regular Training using LAMB
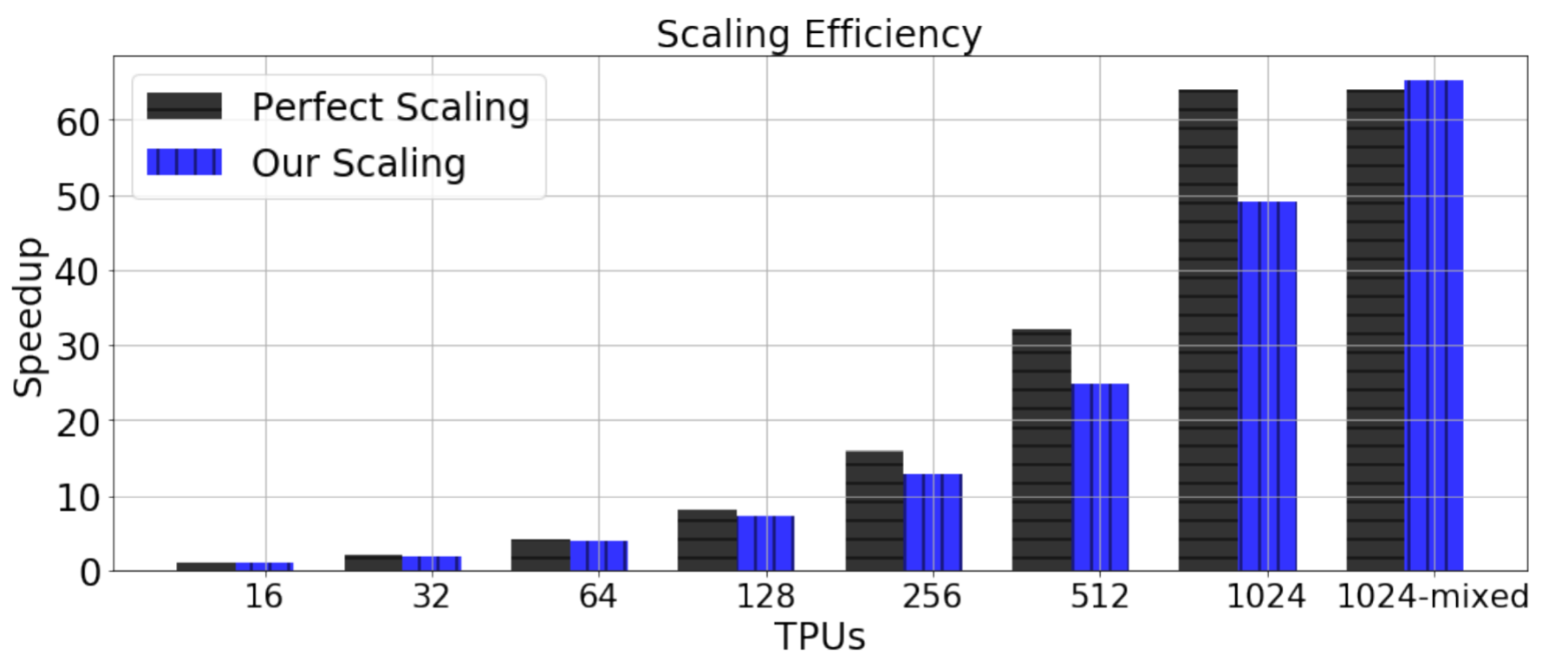
- We achieve 76.8% scaling efficiency (49 times speedup by 64 times computational resources) and 101.8% scaling efficiency with a mixed, scaled batch size (65.2 times speedup by 64 times computational resources). 1024-mixed means the mixed-batch training on 1024 TPUs.
- Comparison with ADAMW and LARS
-
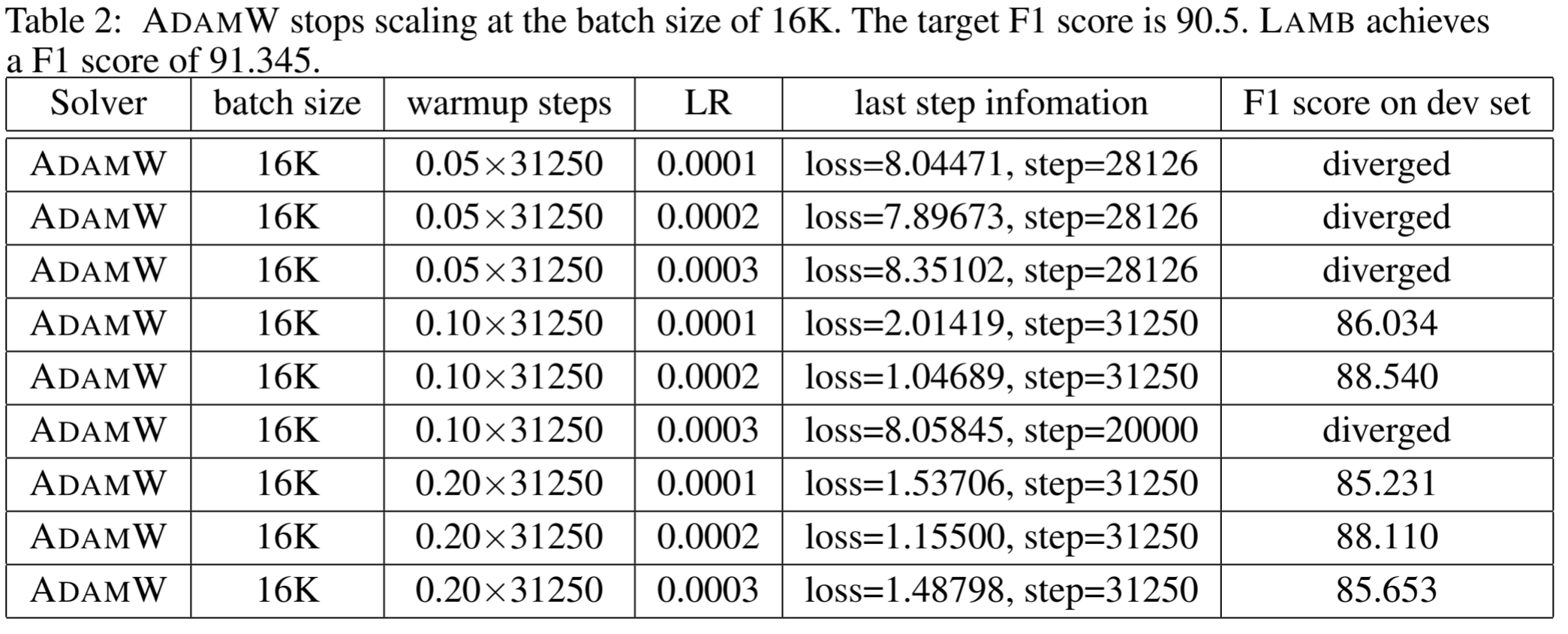
ADAMW stops scaling beyond batch size of 16K because it is not able to achieve the target F1 score (88.1 vs 90.4).We conclude that ADAMW does not work well in large-batch BERT pre-training or is at least hard to tune.
-
We also observe that LAMB performs better than LARS for all batch sizes

-
Doubts:
- What is LAMB trust ratio?