PyTorch RNN
A recurrent neural network (RNN) is a class of artificial neural network where connections between units form a directed cycle.
This is a complete example of an RNN multiclass classifier in pytorch. This uses a basic RNN cell and builds with minimal library dependency.
import torch
from torch import nn
import numpy as np
import pandas as pd
from torch.utils.data import Dataset, DataLoader
from argparse import Namespace
from tqdm import tqdm
Create RNN layer using RNNCell
class ElmanRNN(nn.Module):
def __init__(self, input_size, hidden_size, batch_first = False):
'''
Args:
input_size (int): embedding size?
batch_first (bool): whether the 0th dimension is batch
'''
super(ElmanRNN,self).__init__()
self.hidden_size = hidden_size
self.batch_first = batch_first
self.rnncell = nn.RNNCell(input_size,hidden_size)
def get_initial_hidden_state(self, batch_size):
'''
Return all zeros
'''
return torch.zeros(batch_size,self.hidden_size)
def forward(self, x_in, initial_hidden = None):
'''
Args
x_in (tensor): batch_size * sequence_length * Embedding_size
'''
#print('input shape = ', x_in.shape)
if self.batch_first:
x_in = x_in.permute(1,0,2).to(x_in.device)
#Now x_in (tensor): sequence_length * batch_size * Embedding_size
#print('after modifications for batch_first ', x_in.shape)
seq_length, batch_size, embedding_length = x_in.shape
#Chech if initial hidden state is provided. Else initialize it.
if initial_hidden is None:
initial_hidden = self.get_initial_hidden_state(batch_size)
hidden_t = initial_hidden
hidden_vectors = []
#calculate hidden state vectors by passing through the seqence
for word_batch in x_in:
#print('sequence shape = ', word_batch.shape)
hidden_t = self.rnncell(word_batch,hidden_t)
hidden_vectors.append(hidden_t)
#convert to pytorch hidden vectors
hidden_vectors = torch.stack(hidden_vectors)
#print('hidden vectors = ', hidden_vectors.shape)
if self.batch_first:
hidden_vectors = hidden_vectors.permute(1,0,2)
#print('hidden vectors for batch_first ', hidden_vectors.shape)
return hidden_vectors
Create vectorizer class which generates vectors from surnames
class Vectorizer():
def __init__(self, surname_vocabulary, nationality_vocabulary):
self.surname_vocabulary = surname_vocabulary
self.nationality_vocabulary = nationality_vocabulary
def vectorize(self, surname, vector_length = -1):
surname = surname.lower()
indices = [self.surname_vocabulary.start_index]
#TODO: handle unknown token
indices.extend( [self.surname_vocabulary.token_to_idx[char] for char in surname] )
indices.append(self.surname_vocabulary.last_index)
if vector_length < 0:
vector_length = len(indices)
vector = np.zeros((vector_length,), dtype = np.int64)
copy_length = min(vector_length,len(indices))
vector[:copy_length] = indices[:copy_length]
vector[copy_length:] = self.surname_vocabulary.mask_index
return vector
@classmethod
def from_df(cls, surname_df):
surnames = surname_df['surname'].values
nationalities = surname_df['nationality'].values
surname_vocabulary = SequenceVocabulary()
nationality_vocabulary = Vocabulary()
for surname in surnames:
surname = surname.lower()
for char in surname:
surname_vocabulary.add_token(char)
for nat in nationalities:
nationality_vocabulary.add_token(nat)
return cls(surname_vocabulary, nationality_vocabulary)
Vocabulary class to store index and tokens
class Vocabulary():
def __init__(self , add_unk = False):
self.idx_to_token = {}
self.token_to_idx = {}
if add_unk:
self.unknown_token = '##unk'
self.add_token(self.unknown_token)
def add_token(self,token):
if token not in self.token_to_idx.keys():
index = len(self.idx_to_token)
self.idx_to_token[index] = token
self.token_to_idx[token] = index
return self.token_to_idx[token]
class SequenceVocabulary(Vocabulary):
def __init__(self):
super(SequenceVocabulary,self).__init__(True)
self.mask_index = self.add_token('##mask')
self.start_index = self.add_token('##first')
self.last_index = self.add_token('##last')
Pytorch dataset
class SurnameDataset(Dataset):
def __init__(self, vectorizer, dataframe):
super(SurnameDataset,self).__init__()
self.vectorizer = vectorizer
self.df = dataframe
self.df_active = self.df[self.df['split']=='train']
def set_split(self, split):
self.df_active = self.df[self.df['split']==split]
def __getitem__(self, index):
series = self.df_active.iloc[index]
surname = series['surname']
nationality = series['nationality']
surname_indexed_vector = self.vectorizer.vectorize(surname,args.max_surname_len)
nationality_index = self.vectorizer.nationality_vocabulary.token_to_idx[nationality]
return {'x' : surname_indexed_vector,
'y' : nationality_index}
def __len__(self):
return len(self.df_active)
@classmethod
def from_df(cls, df):
vectorizer = Vectorizer.from_df(df)
return cls(vectorizer,df)
configs
args = Namespace(
surname_csv = r'data\surname\surnames_split_krishan.csv',
epochs = 40,
lr = 0.03,
loss = nn.CrossEntropyLoss,
max_surname_len = 15,
hidden_size = 64,
embedding_size = 16,
model_file = 'rnn_model.pkl'
)
df = pd.read_csv(args.surname_csv)
#Find 95th percentile length
lengths = df[df['split'] == 'train']['surname'].apply(lambda x: len(x))
print('lengths of surnames =\n',lengths.describe())
import math
_95thperc = lengths.sort_values().iloc[math.floor(len(lengths)*0.95)]
print('95th percentile length = ',_95thperc)
args.max_surname_len = _95thperc
lengths of surnames =
count 7680.000000
mean 6.663021
std 1.983061
min 1.000000
25% 5.000000
50% 6.000000
75% 8.000000
max 17.000000
Name: surname, dtype: float64
95th percentile length = 10
Load , analyze data, create data loder
dataset = SurnameDataset.from_df(df)
train_dataloader = DataLoader(dataset,32,True)
num_tokens = len(dataset.vectorizer.surname_vocabulary.idx_to_token) #embedding row size
num_classes = len(dataset.vectorizer.nationality_vocabulary.idx_to_token)
print ('tokens = {}, classes = {}'.format(num_tokens,num_classes ))
df.sample(5)
tokens = 59, classes = 18
| nationality | split | surname | |
|---|---|---|---|
| 2922 | English | test | Renshaw |
| 7833 | Japanese | val | Takaoka |
| 3715 | Arabic | train | Arian |
| 8269 | Italian | train | Serafini |
| 4808 | Russian | train | Chehluev |
Create Model
class SurnameRNNClassifier(nn.Module):
def __init__(self, feature_size, output_classes):
super(SurnameRNNClassifier,self).__init__()
self.embedding = nn.Embedding(feature_size,
args.embedding_size,
dataset.vectorizer.surname_vocabulary.mask_index)
self.rnn = ElmanRNN(args.embedding_size, args.hidden_size, True)
self.linear = nn.Linear(args.hidden_size, output_classes)
self.dropout = nn.Dropout(p=0.1)
def forward(self, x_in, apply_softmax = False):
'''
args
x_in = batch_size * sequence_length
'''
#print('x shape = ',x_in.shape)
yhat = self.embedding(x_in) # batch_size * sequence_length * embedding_dim
#Functional DROPOUT
#no idea whether it's train or eval. Use nn.Dropout
#yhat = torch.nn.functional.dropout(yhat, 0.1)
yhat = self.rnn(yhat) # batch_size * sequence_length(num hiddens) * hidden_dim
yhat = yhat[:, -1, :]
yhat = yhat.squeeze()
#DROPOUT
yhat = self.dropout(yhat)
yhat = self.linear(yhat) # batch_size * output_classes
if apply_softmax:
yhat= torch.nn.Softmax(1)(yhat)# batch_size * output_classes
return yhat
Function to calculate validation loss and accuracy over entire split
import pdb
def calculate_loss_acc(dataset,model,split='val'):
#pdb.set_trace()
dataset.set_split(split)
dataloader = DataLoader(dataset, batch_size=64, shuffle=True)
total = len(dataset)
correct = 0
losses = []
model.eval()
for data in dataloader:
x = data['x']
y = data['y']
yhat = model(x)
loss = args.loss()(yhat,y).item()
losses.append(loss)
yhat = torch.argmax(yhat,dim=1)
correct += torch.sum(y==yhat).item()
loss = sum(losses)/len(losses)
acc = correct/total
dataset.set_split('train')
return loss, acc
Train
model = SurnameRNNClassifier(num_tokens, num_classes )
print(model)
optimizer = torch.optim.SGD(model.parameters(),lr = args.lr)
train_losses, val_losses, val_accs = [],[],[]
max_acc = 0
for epoch in tqdm(range(args.epochs)):
losses = []
for data in train_dataloader:
x = data['x']
y = data['y']
model.train()
yhat = model(x)
optimizer.zero_grad()
loss = args.loss()(yhat,y)
loss.backward()
losses.append(loss.item())
optimizer.step()
train_losses.append(sum(losses)/len(losses))
val_loss, val_acc = calculate_loss_acc(dataset, model)
val_losses.append(val_loss)
val_accs.append(val_acc)
if (val_acc > max_acc):
max_acc = val_acc
torch.save(model.state_dict(),args.model_file)
#print('epoch {} : train_loss {}, val_loss {}, val_acc {}'.format(epoch
# ,train_losses[-1],val_losses[-1],val_accs[-1]))
SurnameRNNClassifier(
(embedding): Embedding(59, 16, padding_idx=1)
(rnn): ElmanRNN(
(rnncell): RNNCell(16, 64)
)
(linear): Linear(in_features=64, out_features=18, bias=True)
(dropout): Dropout(p=0.1)
)
100%|██████████████████████████████████████████████████████████████████████████████████| 40/40 [02:25<00:00, 3.82s/it]
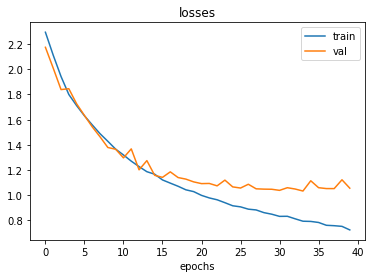
import matplotlib.pyplot as pp
pp.xlabel('epochs')
pp.title('losses')
pp.plot(train_losses)
pp.plot(val_losses)
pp.legend(['train','val'])
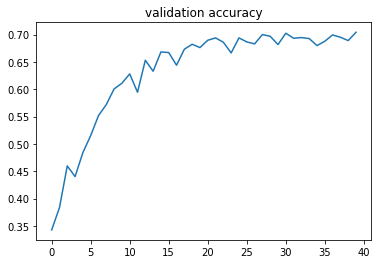
pp.figure()
pp.plot(val_accs)
pp.title('validation accuracy')
pp.show()
#Fetch best model
model.load_state_dict(torch.load(args.model_file))
val_loss,val_acc = calculate_loss_acc(dataset,model,'val')
print('val loss and acc = ', val_loss,val_acc)
test_loss,test_acc = calculate_loss_acc(dataset,model,'test')
print('test loss and acc = ', test_loss,test_acc)
val loss and acc = 1.0600555860079253 0.7042682926829268
test loss and acc = 1.1671412655940423 0.6825301204819277
def predict(surname):
model.eval()
x = torch.LongTensor(dataset.vectorizer.vectorize(surname)).view(1,-1)
oindex = torch.argmax(model(x)).item()
nationality = dataset.vectorizer.nationality_vocabulary.idx_to_token[oindex]
#print ('Nationality for {} is predicted as {}'.format(surname, nationality))
return nationality
predict('Subudhi')
'Japanese'
count = 0
total_count = 10
for i in np.random.randint(0, len(df),(total_count,)):
row = df.iloc[i]
isSame = row['nationality'] == predict(row['surname'])
print('surname = {: <15}, original = {: <10}, predicted = {: <10}, Correct = {}'
.format(row['surname'], row['nationality'], predict(row['surname']),isSame))
if isSame:
count += 1
print('acc = ',count/total_count)
surname = Stevenson , original = Scottish , predicted = English , Correct = False
surname = Ughi , original = Italian , predicted = Japanese , Correct = False
surname = Kartoziya , original = Russian , predicted = Japanese , Correct = False
surname = Issa , original = Arabic , predicted = Japanese , Correct = False
surname = Webb , original = English , predicted = German , Correct = False
surname = Shadid , original = Arabic , predicted = English , Correct = False
surname = Yuferev , original = Russian , predicted = Russian , Correct = True
surname = Stroud , original = English , predicted = English , Correct = True
surname = Paterson , original = English , predicted = English , Correct = True
surname = Idane , original = Japanese , predicted = Japanese , Correct = True
acc = 0.4