Spark Quickstart on Windows 10 Machine
Apache Spark™ is a unified analytics engine for large-scale data processing.
Install java
Install spark (2 ways)
-
Using pyspark (trimmed down version of spark with only python binaries).
spark programs can also be run using java, scala, R and SQL if installed using method 2 while pyspark only supports python.
conda create -n "spark" pip install pyspark -
Using spark binaries
-
download spark binaries

-
Install 7zip for winodows 64 bit and extract spark-2.4.4-bin-hadoop2.7.tgz
PS C:\Users\krkusuk.REDMOND\bin> dir .\spark-2.4.4-bin-hadoop2.7\ Directory: C:\Users\krkusuk.REDMOND\bin\spark-2.4.4-bin-hadoop2.7 Mode LastWriteTime Length Name ---- ------------- ------ ---- d----- 8/27/2019 2:30 PM bin d----- 8/27/2019 2:30 PM conf d----- 8/27/2019 2:30 PM data d----- 8/27/2019 2:30 PM examples d----- 8/27/2019 2:30 PM jars -
Add bin directory to PATH environment variable
C:\Users\krkusuk.REDMOND\bin\spark-2.4.4-bin-hadoop2.7\bin
-
Test spark installation
Check your spark installation directory in anaconda powershell.
(spark) PS C:\Users\krkusuk> gcm pyspark
CommandType Name Version Source
----------- ---- ------- ------
Application pyspark.cmd 0.0.0.0
C:\Users\krkusuk\AppData\Local\Continuum\miniconda3\envs\spark\Scripts\pyspark.cmd
> pyspark
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.4
/_/
Using Python version 3.7.4 (default, Aug 9 2019 18:34:13)
SparkSession available as 'spark'.
>>> spark.version
'2.4.4'
Winutils error fix :
If seeing a bunck of java related errors while starting spark, install winutils using this link .
Download data
Download usda employment website to run analysis.
Unzip the file
Play with spark shell
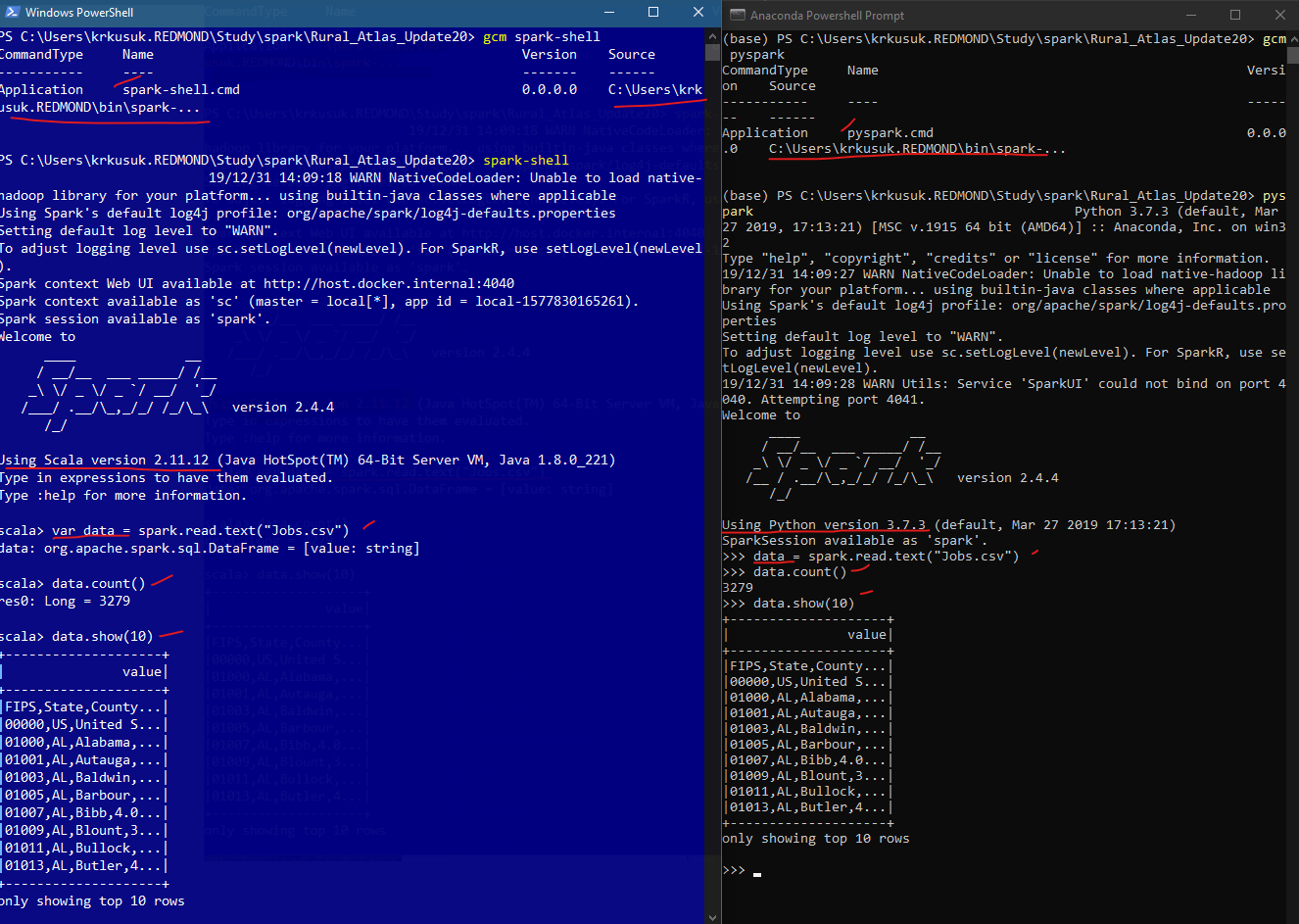
Setting log Level to WARN
-
If installed spark through pyspark.
Problem with setting loglevel in pyspark 2 solutions that worked for me.
-
Through config file
Get spark home
>>> import os >>> os.environ["SPARK_HOME"] 'C:\\Users\\krkusuk\\AppData\\Local\\Continuum\\miniconda3\\envs\\spark\\lib\\site-packages\\pyspark'Create conf folder and log4j.properties file inside conf folder. Write these inside the file.
# Set everything to be logged to the console log4j.rootCategory=WARN, console log4j.appender.console=org.apache.log4j.ConsoleAppender log4j.appender.console.target=System.err log4j.appender.console.layout=org.apache.log4j.PatternLayout log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n -
Through code
spark = (SparkSession .builder .appName('PythonEmpAnalysis') .getOrCreate()) spark.sparkContext.setLogLevel('ERROR')
-
-
If spark is installed through binary download
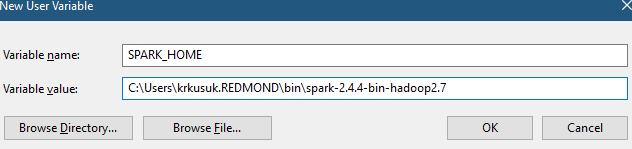
Set your environment variable SPARK_HOME to root level directory where you installed Spark on your local machine.
To avoid verbose INFO messages printed on the console, set rootCategory=WARN in the conf/ log4j.properties file.
Rename log4j.properties.template to log4j.properties
log4j.rootCategory=WARN, console
Run full spark program
Download emp_analysis.py script.
(base) PS C:\Users\krkusuk.REDMOND\Study\spark> spark-submit .\emp_analysis.py .\Rural_Atlas_Update20\Jobs.csv
Results
+-----+--------+
|State|Counties|
+-----+--------+
|TX |255 |
|GA |160 |
|VA |135 |
|KY |121 |
|MO |116 |
+-----+--------+
only showing top 10 rows
Unemployement per states
+-----+------------------+
|State|AvgUnempRate2018 |
+-----+------------------+
|PR |11.106329113924046|
|AK |8.616666666666665 |
|AZ |6.59375 |
|WV |5.864285714285716 |
|DC |5.6 |
+-----+------------------+
only showing top 10 rows
Unemployment in Washington state
+-----+-----------------+
|State| AvgUnempRate2018|
+-----+-----------------+
| WA|5.597499999999999|
+-----+-----------------+
Run
spark-submit.cmd .\emp_analysis.py .\Rural_Atlas_Update20\Jobs.csv
Jypyter notebook
-
pyspark
conda env <env_name> jupyter notebook -
Binary download
Set environment variables.
Name Value SPARK_HOME D:\spark\spark-2.2.1-bin-hadoop2.7 HADOOP_HOME D:\spark\spark-2.2.1-bin-hadoop2.7 PYSPARK_DRIVER_PYTHON jupyter PYSPARK_DRIVER_PYTHON_OPTS notebook pyspark command will be linked to jupyter notbook now.
Adding external JARS
-
In code
pyspark.config('spark.jars', <jar_full_path_with_name>) -
Copy jar to $SPARK_HOME/jar
-
While starting pyspark or spark-submit
pyspark --jars <jar_full_path_with_name>
Spark Documentation on submitting applicaitons
How spark works
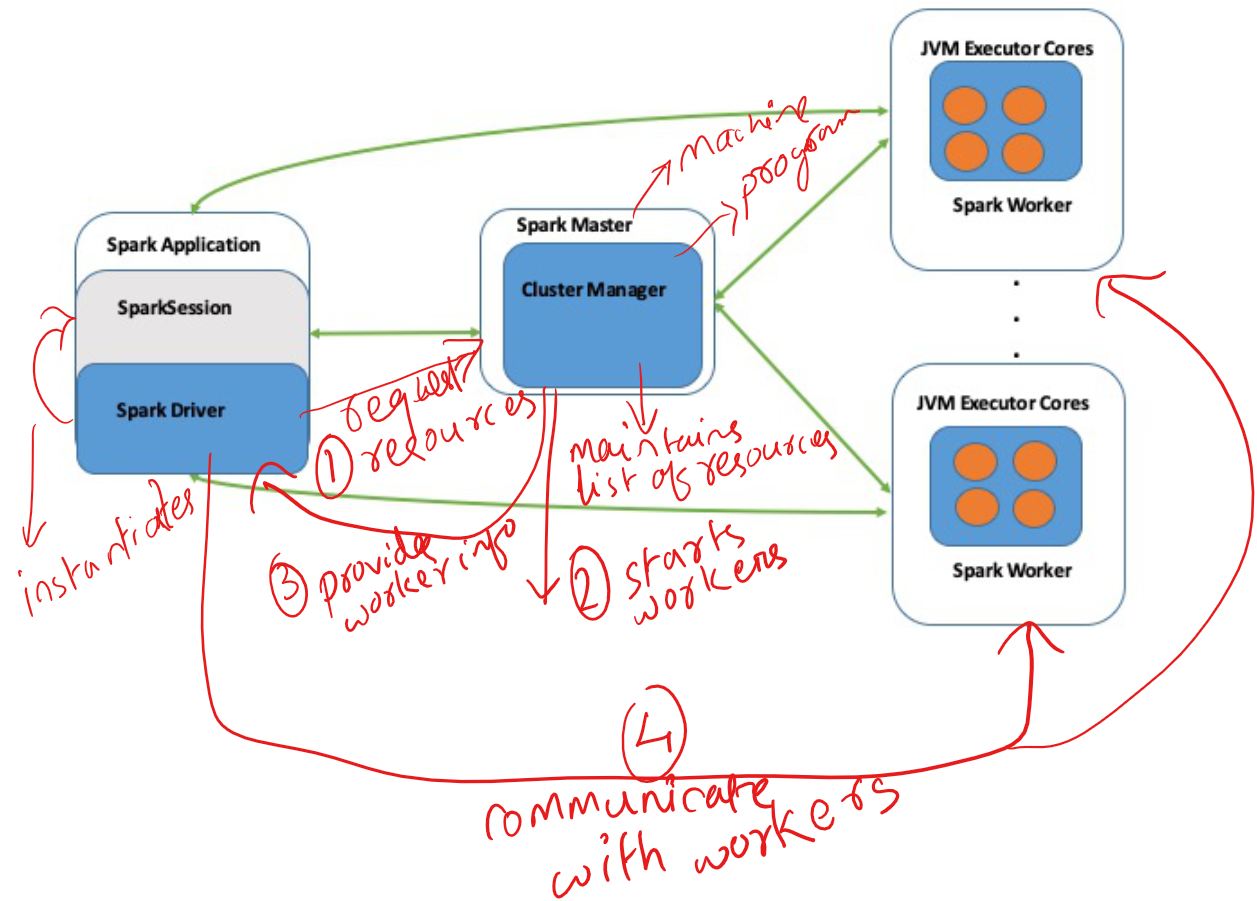
Base image extracted from book
Github Practice project
To practice more on different functionalities of spark, follow my sparkpractice project in github.
Other Tutorials
Troubleshooting
-
When things are not working even if configurations are correct, stop every session, close jupyter notebooks and restart.
- If facing issues with jars, try downgrading spark version.
- I am still facing hive related issues while saving dataframes as managed tables and trying to figure out a solution. The solutions proposed are to restart session and system but nothing works. Probably, it’s a windows related issue.
-
For jobs invoving bigger datasets, working on a cloud deployment of spark cluster is recommended.
- Currently there are issues with Azure HDInsight. See my blog on HDInsight challenges.
- The above HDInsight blog has a solution which runs on AWS EMR.
- Another option is to use databricks who are also the founders of spark. They provide a free community edition to try out.
- Azure has a databricks product which can be explored too.
Feedbacks are welcome. :-)